#excel relative vs absolute cell reference
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text
Advanced Excel Formulas
It is important for you to understand this part especially if you need excel homework help.
Cell Referencing and Relative vs. Absolute References:
Understand the importance of referencing cells.
Differentiate between relative and absolute references for accurate formula copying.
Example: =A1 * $B$1
a. IF Function:
Learn how to use the IF function for logical decision-making.
Example: =IF(D2>70, "Pass", "Fail")b. VLOOKUP Function:
Perform vertical lookups to find data in a table.
Example: =VLOOKUP(A2, E2:F10, 2, FALSE)c. SUMIF Function:
Sum values based on a specific condition.
Example: =SUMIF(C2:C20, ">100", D2:D20)
After all, feel free to contact with us to hire excel expert to do my excel assignment in USA.
0 notes
Photo

Let’s talk about sex, baby! Let’s talk about Ge-e-enes! Let’s talk about all the good things and the bad things that your whelp might be!
Alright, so when A Canon Warlord and a theoretical partner love each other very much, chances are they’re going to reproduce, as warlords are known to do. One key aspect of reproduction between two organisms involves handing down genes.
A gene is a unit of heredity which is transferred from a parent to offspring and is held to determine some characteristic of the offspring. There are two types of genes which will be important in determining how Gunmar’s offspring turn out. These are called Dominant (D) and Recessive (D) genes.
The offspring receive one version of a gene, called an allele, from each parent. If the alleles are different, the dominant allele will be expressed (meaning the character will have that aspect from their parent), while the effect of the other allele, called recessive, is masked (meaning the other parent’s aspect comes through) While we aren’t lucky enough to have Bular’s mother for a reference, by comparing what he has in common with his father vs what is different, we can get a rough idea of out local suckbags dominant and recessive genes..
Ears, horns, and eyes.

Gunmar has Tiny, almost invisible ears, possibly internal ones. While some other trolls are shown to have external ears, Bular doesn’t, so we can guess that Tiny Ears is a dominant trait. While you’d think such Big Horns would be large and in charge, Bular’s horns are closer to a rams, so Gunmar’s offspring won’t inherit those recessive Big Horns unless the other parent has a similar set. Gunmar’s eyes are always glowing, and Bular’s glow as well. So Glowy Eyes are Dominant genes!
Snoot and Frame

Gunmar and Bular both share the exact same Snaggletooth grin. Their teeth are uneven, bigger on one side than the other. so Snaggletooth Grin would be a dominant gene, and likely unless the mother’s jaw structure is also dominant, in which case, the offspring might end up a little bit of both jaw structures. This is called Co-dominance. Likewise, Gunmar’s Bulky Frame is evident in Bular’s chest and shoulders. So Dominant Bulky Frame is a go!
Hands, Feet, And Tail

Gunmar’s hands are tipped with four Brutal Claws, excellent for ripping and digging. Bular’s claws are exactly the same, if not a bit stubbier. So Brutal Claws are likely a dominant or co-dominant gene. The trolls in Trollmarket are shown to have dozens of different foot type, from toes to cloven. Gunmar has elephant-like Heavy Hooves. Bular’s hind legs are the same, so we can assume the skullcrusher’s Heavy Hooves are dominant. The same can be said of his broad, Dominant alligator tail.
Melanism and Albinism

While we have evidence of albino trolls existing (Eloise Stemhower) Gunmar shows no sign of either of these genes.
Stone Color, Eye Color, Rune Color

Gunmar’s stone is dark blue to gray in coloration. While Bular’s hide isn’t exactly the same, it’s still a Dark Shade. So we’ll say Dark Shade is a dominant stone color. One of Gunmar’s more striking features are his small, Piercing Blue eyes. However, Bular’s eyes are a vibrant, fiery red. So it would seem that Piercing Blue Eyes are a recessive trait. Both Bular and Gunmar have Dark Colored Horns. So if Bular’s mother had paler horns, they were outshone by the dominant Dark Colored Horns.

These genes refer to the color, pattern and frequency of Gunmar’s Runes, which don’t show up on Bular. It’s possibly they’re artificial, like tattoos, but if the Runes are a gene, then they’re a recessive one.

Neither Gunmar nor Bular have problems with blood clotting, so Healthy Blood is probably a dominant gene.
Unfortunately, at six thousand years old, Gunmar only has one child that we can absolutely be sure about. That suggests he has Very Low Fertility as a Domiant Gene. possibly even recessive infertility.
The C and D are a possible bloodtype, which suggest what Antigens Gunmar’s Immune system carries. Antigens are molecules. They can be either proteins or sugars. The types and features of antigens can vary between individuals, due to small genetic differences. The antigens in blood have various functions, including: transporting other molecules into and out of the cellmaintaining the structure of red blood cells detecting unwanted cells that could cause illness. If Bular’s mother had either a C antigen or a D antigen, then Bular’s immune system wouldn’t be as well defended, because it’d only recognize half as many antigens as it might if Bular’s mother had a different Bloodtype (for example G and H. If Bular is exposed to C, D, G, and H antigens, then he as defense against the different illnesses that target each. If he only had C,D and H, then he’d have fewer protections. Three compared to four.)
These are all theoretical, and done using Niche a genetic survival guide as a basis. I am not an expert in Genes, only shipping, and all the information located in this post came from google. Remember, this is just a rough guide. Your OC Gunmar relatives can look or behave any way you’d like!
54 notes
·
View notes
Link
Excel Relative and Absolute cell references behave differently when copied and filled to other cells. In this video tutorial, you'll learn how and when to use both types of cell references in Excel.
#excel tutorial#excel tip#excel training#excel cell reference#excel relative vs absolute cell reference#excel relative cell reference#excel absolute cell reference#excel formulas#excel functions#excel help#microsoft excel tutorial#microsoft excel training#goaskdebbie#go ask debbie
0 notes
Text
Linking Techniques In Depth In Excel
Linking between spreadsheets, workbooks and applications offers huge efficiencies but needs a clear understanding to work accurately and avoid risks that linking can pose.
Understand and apply the power of linking techniques within Excel and other key MS Office applications to boost productivity and efficiency for you and your organization.
Object Linking and Embedding (OLE) makes content that is created in one location or program available in another program.
As an example, in Excel, you can link or reference to other cells in a worksheet or other worksheets, external workbooks, external files, and pages on the internet or your intranet.
Dynamic links ensure changes in source data, graphics, charts, etc. are reflected in all "dependent linked" files. Mastering the linking of information using MS Excel and MS Office is a valuable and marketable skill.
Why Should You Attend
» Use data more efficiently and effectively » Ensure improved data accuracy » Improve job satisfaction, team performance, and professionalism » Impress your management, peers, and clients » Advance all co-workers using MS Office to a consistent standard » Maximize your technology investment performance
Areas Covered
» The link between Excel worksheets and external files » Relative Vs absolute references » Complex formulas linked to external data » Formula Auditing » Update linked values » Change link source » Open a source file » Break links » Link information and graphics between Excel, Access, and other programs » Hyperlink to other workbook cells, external files, and web pages
Who Will Benefit
Any person or organization seeking to significantly boost efficiency, productivity, job satisfaction, and effective use of their technology investment. Particularly personnel in the following fields:
» Accounting » Banking » Business Analysis » Economics » Finance » Insurance » Investment » Management » Statistics » Valuation To Register (or) for more details please click on this below link: https://bit.ly/3xNA9BB/a> Email: [email protected] Tel: (989)341-8773

0 notes
Photo

Getting Iffy With it
Adventures in Excel
If you've been following along, we discussed in the last several posts of this series how, if you're not working in a very "tech forward" organization (like my two compatriots on his site), but you have the same title, you're probably obtaining your data from another department (or it might be a sentient sponge, or a gang of squirrels with dreams of world domination, you'll actually have no idea) who you will have no contact with. As a side effect of this...rather strange situation (ya know, like being a child and being abandoned briefly by your mother in a laboratory into the care of a stranger in order to track your response...what, no other Bowlby heads out there?) you'll almost certainly get this data in a form that is completely unusable until you , dear reader, get your hands on it. As such, in this post, we'll begin to dive into the myriad ways in which you might go about doing that, but first, I need to put you in the right frame of mind, I am a therapist, after all. Remember back to one of my first posts: when you get down to it, all computer code boils down to a series of binary choices (generally represented as 1s and 0s) indicating that a specific gate on the actual hardware is "on" or "off", and by layering millions of these on top of each other is how every single piece of computer software you have comes into being. Think about other binary decisions you've made in your life: Yes, or no, Odd or Even, Coke or Pepsi (despite what RC cola would like you to think), and perhaps the most bemoaned of all for everyone who has ever been a student: True or False. Interestingly, this true/false dichotomy is the very essence of how all of the chopping and screwing you'll be doing on your messy data (and in fact, the majority of all computer programming) begins; by simply asking Excel if what you typed in is true...or false. Now that you've been successfully induced, we can jump into the the technical stuff. As you may have garnered from my post about formulae, Excel actually has, DEEP within it's bowels, a fairly robust programming language underpinning it: Visual Basic for Applications (VBA). Now, there are two general ways to tap into it: The way that the majority of wizards do it: through the function bar (that is, typing an "=" and letting it rip), and... The way that the particularly adept wizards engage in it: through the command line, which I'm not going to bother touching here, because if you're writing entire Excel spreadsheets in VBA, why are you still using Excel? Move onto Python or R and continue feeling smugly superior! So, with that being said, how does one tap into this unlimited wellspring of potential using nothing but the features on the Excel mainpage? Well, I already told you, simply ask Excel =If() ! All flowery language and allegory aside, the majority of computer programming languages (the one underneath Excel included) hinge on this "If" statement, the only difference is how the particular language wants you to write these statements. In the Excel parlance, when one types in =If( you'll be asked for three things separated by commas (that Excel could really make a bit clearer), they are: The logical argument (AKA, what do you want Excel to check as being true or false?) A good example would be say "Does the value in Cell A1 equal the value of the Cell in B1?" which would be written as =if(A1=B1 (Protip!, unlike other programming languages, the way you write "does not equal" in Excel is <> ) The value you want to grab if the value is true (leaving this blank will just write "true") but in this case, let's make it say "Yes". This will be written as =if(A1=B1,"Yes".(Protip!, within Excel, if ever you want to return something other than a number you always need to surround it in quotation marks.) The value that you want to return if the value is false (leaving this blank will just write "false") in this case, let's make it say "No". This will be written as =if(A1=B1,"Yes","No"). After completing this formula with the three elements followed by a closing parenthesis, you'll get a cell that either says "Yes" or "No" depending on if A1 and B1 contain the same values. The powerful thing here is what comes next: by double clicking the lower right hand corner of the cell with the formula, it'll automatically populate all of the rows which are adjacent to information with Ax = Bx (where x equals the row number) allowing you to check each row to see if the two columns match! To add an extra wrinkle, let's say you want to check to see if each cell in a column is equal to the values in a specific cell, you'd do that as follows: =if(A1 = $B$1,"Yes","No"). If you then double click the cell as you did before, that will check every value in column A against ONLY the value in B1. By adding the dollar sign to the location of the cell, You've identified the "Absolute Reference" as opposed to the "Relative Reference". Feel free to disregard these names immediately, and start referring to it as "dollar sign". You can even manipulate it by only using the Absolute reference on the row (A$1) OR the column ($A1) if you're populating , vertically, horizontally, or both (yes, technically putting B$1 in the above example would have gotten you the same answers). In summation, in this post we've learned: Excel is actually built on top of a "real" programming language called VBA. You can write tiny programs in Excel through the function bar (or big programs through the command line...showoff). All "programming" really is, is the manipulation of true/false statements underpinning the binary code even further beneath all computational tasks. How to write your own "If" statement in Excel and how to "phrase" the returning of numbers vs. anything else using quotation marks. How to utilize the absolute reference (AKA the "Dollar Sign") to change what gets included in the statements in each line of your spreadsheet. Next time, we'll get more grammatically complex, leveraging Ands and Ors in our Ifs. We might even get crazy and throw some Ifs in our Ifs...so you can drive while you drive. Ever Upward, -Snacks
- Max Mileaf Read post
1 note
·
View note
Text
What Are Cryolipolysis Results?
Cryolipolysis Declares To Eliminate Fat Cells Via The Skin
Content
Treating Fat Pockets.
Therapy Day.
After Your Treatment.
The effects of Cryolipolysiss should begin within a couple of weeks with the full effects taking 2-3 months. Each location will certainly last 50 minutes, nonetheless with our latest sophisticated devices that includes 2 heads rather than one, unlike our competitors, we can treat 2 areas at the very same time. LED COLOUR TREATMENT stimulates collagen production, blood flow and Citochromes, healthy proteins that respond to light and colour to generate natural biochemical response in the skin. A lot of reports concerning CLL included in this review did not have strenuous scientific method in research layout or in result measurement.
CoolSculpting vs. Kybella: Doctors Explain the Differences - NewBeauty Magazine
CoolSculpting vs. Kybella: Doctors Explain the Differences.
Posted: Fri, 23 Aug 2019 07:00:00 GMT [source]
It is important you feel great that you have chosen a therapy that is ideal for you. Some bruising of the treatment area that can last for up to 5 days. Fat cells freeze from -1 degree so a lower temperature level is not required. Remember we can also tie training courses with each other to conserve you time and money.
Dealing With Fat Pockets.
We discover that it is important to take pictures so you can see for yourself the distinction in order to completely value the difference in appearance. Skin texture as well as appearance is as essential to clients as the real inch loss. Our pictures do not include your face, so you can never be identified. However we will just ever share your photos on our social media sites or in our center if we have gotten your grant do so. No, the excellent aspect of the Cryolipolysis solution is that you can set about your day as normal. We do recommend you to increase your water intake by 2 litres to help with the fat elimination.
Is CoolSculpting a hoax?
Research generally points towards CoolSculpting being a relatively safe and effective treatment for removing some areas of fat. A 2015 review published in Plastic and Reconstructive Surgery analyzed 19 previous studies of cryolipolysis.
Our programs are for individuals that already hold a minimum appeal qualification of NVQ Level 2/3 or equivalent and also wish to broaden their therapy offering. Cryolipolysis is ideal applied to surface fat pockets and ideal referred to as sculpting and improvement for customers wanting to target persistent areas of concern. To find out more and to book an examination to review cryolipolysis at the Hilton Skin Center in Reading pleasecontact ustoday. To begin with you will feel an experience of yanking as the applicator draws in the area, this ends up being much less evident after a couple of mins. My people are after that fairly pleased to rest and review, listen to music or play with mobile devices while the treatment session proceeds. This more recent way of targeting and also minimizing areas of undesirable fat, without the demand for surgical incisions, appropriates for both men and women to tame their 'shaky bits'.
Treatment Day.
To reserve a cost-free appointment or this therapy, please call our friendly team now. For real-life before and after instances showing the effectiveness of this treatment as well as our other remedies watch our results page. You can expect to be able to resume your routine life quickly, making it the excellent lunch break therapy. There's no demand for anaesthetic with Fat Freezing and also the skin's obstacle is not compromised, leaving you to continue with your regular daily regular recognizing that you'll be entrusted secure as well as natural results. This will certainly be redeemed versus the expense of a Cryolipoysis treatment if scheduled on the day of the assessment.

Everybody, both men and women, have areas of stubborn fat, or 'wobbly little bits' as I like to call them, that we 'd like to see gone, and also diet regimen as well as workout isn't constantly the simple answer. Clinicbe ® has an all natural approach to skin care, exceeding the prompt concern of its patient to understand and also treat the person all at once.
Take photos every 2 weeks and compare them versus each other. Unlike our competitors, our treatment mug covers 360 degrees of the cup area-- not just the sides. As it's a procedure done by an expert, it can uniquely target anywhere, such as stomach, thighs, or arms, to ensure that the individual can choose their problematic areas. Your specialist will certainly take some prior to images and also increase the area you desire to treat.

More study should be motivated to show with methodological rigour positive effects of this treatment modality and to figure out categories of people in whom many favourable end results might be expected. A retrospective cohort research study between April 2016 and August 2018 was carried out. Thirty-five people underwent a solitary 45-minute cycle of cryolipolysis to the submental region utilizing the Coolsculpting System. step-by-step article aims to analyze the volume loss making use of a three-dimensional evaluation complying with submental cryolipolysis. None of the scientist's clients revealed any reoccurrences of their preliminary complication for which they were treated. Take girth dimensions of dealt with locations such as arms, midsection as well as thighs.
You need to wait a minimum of 3 months after normal birth of your child or a minimum of year after a C area. It is best to get General Practitioner authorization blog post giving birth before starting with therapy. You might see outcomes after 2-4 weeks but the full results will certainly be seen after 8-12 weeks. https://oxfordshire.lipofreeze2u.co.uk/ do request that you come back at week 6 for an acting follow up and then once again at week 12 for a final procedure as well as photo if proper. These comply with ups are completely free of charge so there are no added fees for this service. Ought to you have any kind of worries or queries either before or after your treatment after that you are greater than welcome to pop into the salon for a chat or provide us a telephone call on If you would like a free appointment to talk about therapy in London you can also organize that on this site as well.
Should I wear Spanx after CoolSculpting?
We recommend wearing compression garments (Ex: Spanx, or Under Armour ) for 1-2 days after treatment, especially if the abdomen or flanks are treated. This may help alleviate pain and decrease swelling. Following the procedure, a gradual reduction in the thickness of the fat layer will take place.
She will certainly position you on the treatment table and also make you comfortable. A protective gel membrane layer is put onto the location as well as the tool is connected. During the therapy you can unwind as well as enjoy TELEVISION or use our totally free WIFI. No certain care is called for after treatment, so you can resume your regular task instantly after that, including job as well as sport. Follow a healthy well balanced diet plan to maintain or lower your weight as wanted.
Dr Barbara Kubicka has actually combined a distinct team of specialists to offer individual a wide series of medical care services. Cryolipolysis is absolutely non-invasive, so there are no scalpels or needles involved and there is no need for anesthetic or sedative. People usually describe therapy as 'weird however bearable' and as the cool begins, the sensation is normally decreased. Some really discover it quite loosening up, as they have the ability to rest, read, conversation or search their phones while therapy is happening. It is excellent for clients that have stubborn areas of fat which are withstanding the impacts of diet plan or workout.
#cryolipolysis cost uk#cryolipolysis treatment near me#cryolipolysis at home#cryolipolysis before and after#cryolipolysis near me#cryolipolysis reviews#fat freezing reviews#fat freezing at home#fat freezing treatment#fat freeze near me#does fat freezing work#fat freezing before and after#fat freeze review#coolsculpting near me#coolsculpting reviews#coolsculpting before and after#coolsculpting at home#does coolsculpting work#coolsculpting stomach
0 notes
Text
Bose Noise Cancelling Headphones 700 vs. Sony WH-1000XM4: Which Pair Is Better?
There was a time when Bose alone ruled the active noise cancellation (ANC) landscape, and all other headphones claiming to tamp down ambient noise weren't nearly as effective or were even more expensive. But things are changing, and while the Bose Noise Cancelling Headphones 700 offer some the best ANC we've tested, other models are catching up. Of the top contenders, Sony's WH-1000XM4 noise-cancelling headphones clearly stand out, with excellent ANC and an arguably better audio experience. But which pair is right for you? Let's break it down category by category to help you figure it out.
Which Headphones Have Better Noise Cancellation?
Let's start with hiss. In a quiet room, turning the noise cancellation on each should tell us if either model is adding high-frequency hiss to the equation—a common trait in ANC headphones, especially lower-tier models that use the hiss to mask frequencies they have trouble cancelling out.
In high-performance pairs like these, we expect to hear little or no hiss. This is the case with the Bose Noise Cancelling Headphones 700—in a quiet room, turning the ANC on to maximum level actually manages to make the room even quieter. The Sony WH-1000XM4 headphones produce some audible hiss, but just barely, and certainly not enough to make or break your decision.
Of course, the hiss test says nothing of what the headphones do to cancel out actual noise, from the whir of an AC unit to the rumble of an airplane. We started by comparing the headphones against the same deep low frequencies played at high volume over near-field monitors to give us an idea of how the ANC circuitry handles deep rumble like you hear on a plane or train.
With the ANC at maximum level (10) on the Bose model, the low-frequency audio cancellation is impressive. You still hear the rumble, but much of the low-frequency intensity is diminished. The Sony model actually seems to dial back some of the deepest low frequencies even more, while both let through some of the higher frequencies associated with the rumble. So while the Sony model does produce some hiss, it's slightly more effective against loud low-frequency rumble.
Tested against the same recording of a loud restaurant, the Bose Noise Cancelling Headphones 700 do a solid job of dialing back the overall volume, as do the Sony WH-1000XM4. It's close, but we give the edge here to the Sony model, which seem to lower the overall volume level just a bit more.
With loud rock music playing through nearby speakers, the Bose Noise Cancelling Headphones 700 and the Sony WH-1000XM4 both offer dramatic reductions in volume. The Bose headphones seem to let fewer of the highest frequencies through, but are slightly less effective with the mids and lows. The Sony headphones cut out a larger swath of low and mid-range frequencies, but leave more of the highs to be heard, creating an odd filtered effect. This, in particular, is quite a stress test—that either pair effectively reduces such a loud signal with both booming lows and bright highs is impressive. It seems unlikely that you'll ever be using ANC headphones in a real-world scenario like this, but it gives us an idea of what the circuitry for each model can do when pushed to the limit.
When we lower the music to a level you might experience in a restaurant or bar, and combine it with the crowd chatter, we have a more useful test. In this scenario, both headphones perform quite well, and it becomes a bit like splitting hairs. Generally speaking, we'd say that high-mid and high-frequency content seems to slip past the Sony WH-1000XM4's circuitry just a bit more than with the Bose Noise Cancelling Headphones 700, while both do a laudable job of eliminating the lows and low-mids.
So the Bose Noise Cancelling Headphones 700 produce little or no hiss and are generally excellent for noisy environments, while the Sony WH-1000XM4 headphones are slightly more effective at tamping down deep low-frequency rumble, but also produce a bit of audible hiss. It's easy to give the edge to Bose here if you approach this category with purity in mind—the lack of hiss is impressive. But if you're trying to tamp down sounds like airplane and train rumble, you might actually prefer the Sony model.
Which Pair Sounds Better?
Bose is notoriously secretive about publishing specs, while Sony is relatively transparent. Thus, we can tell you that the WH-1000XM4 headphones employ 40mm drivers that deliver a frequency range of 4Hz to 40kHz, although that seems to refer to when the headphones are used in wired mode (and regardless, 4Hz and 40kHz are optimistic values for any frequency range). Both the Noise Cancelling Headphones 700 and the WH-1000XM4 are compatible with Bluetooth 5.0 and support AAC and SBC codecs, but not AptX.
The Bose Noise Cancelling Headphones 700's sound signature is a little brighter and more exaggerated in the lows than the Sony model. It's balanced, but perhaps overly bass-heavy and bright for audiophiles. And with no EQ to tweak the audio experience, what you hear is what you get.
The Sony WH-1000XM4 headphones deliver a bass-forward sound signature, with plenty of sculpting in the highs and high-mids. It's a balanced sound despite all of the sculpting—expect more kick drum thump in the lows and more crisp treble edge lending itself to vocals and higher-register instruments. And you can tweak the balance in the app's EQ.
When it comes to microphone performance, Bose's four-mic array offers slightly more clarity, for a cleaner sound overall, while the Sony mic picks up a little more low-end, so things sound less thin. Callers should be able to understand you easily through both models, provided you have a reliable cell signal.
Beyond Basics: Accessories, Apps, and Battery Life
Both models come with nicely designed, flat zip-up carrying cases with built-in loops for hanging. Both also ship with an audio cable for passive listening, and the Sony model includes an airline jack adapter.
The Bose app (for Android and iOS) offers excellent granular control of the ANC/Ambient modes, but lacks much beyond this. The app allows you to set up either Alexa or Google Assistant as your voice assistant, which you can access via a dedicated button on the headphones (Siri is also always accessible on iOS devices). Other than this, there are some minor tweaks you can make in the settings menu, but there is no changing the EQ for a different sound signature.
The Sony Headphones Connect app (for Android and iOS) includes audio extras like 360 Sound, an immersive audio effect that we find underwhelming. There's also an Adaptive Sound Control feature that tailors the audio performance based on your environment—basically, the overall sound signature and volume will adjust slightly based on the ambient volume levels around you. Purists will want to leave this and 360 Sound off, but they're harmless inclusions. The included five-band EQ is far more useful, and represents an area where Sony gives you a lot more control over the audio than Bose does. The app has a slider to blend ambient and ANC modes, but you can also turn both off, unlike with the Bose app. Beyond this, there are basic changes you can make to the headphone settings, including assigning various functions to the Custom button on the left earcup.
Sony estimates battery life to be roughly 30 hours (or 22 hours when using the headphones with ANC on in cabled mode), while Bose estimates battery life to be up to 20 hours. Ultimately, your results will vary drastically based on your volume levels and your use of ANC and other extra features.
The Absolute Best Noise-Cancelling Headphones (Spoiler: It's a Tie!)
The Bose Noise Cancelling Headphones 700 retail for $379, but can often be found for closer to $300. The Sony WH-1000XM4 noise-cancelling headphones go for $349, but look to be on sale at most retailers for $278 as of this writing. Keep in mind prices fluctuate, especially during the holidays, so we'll put it this way: As long as you're willing to do some moderate hunting online, price shouldn't really be the determining factor when choosing between these two pairs.
Ultimately, the Bose Noise Cancelling Headphones 700 eke out a victory in the noise cancellation department thanks to a lack of added hiss. As for audio performance, Sony's WH-1000XM4 headphones provide a better balance of lows, mids, and highs, and they also offer EQ. At the end of the day, both pairs earn the same rating from us because it comes down to whether you prefer slightly better noise cancellation or slightly better sound quality. The good news is that both are nearly as good as you can get in either category, so you're not making a major sacrifice by selecting one over the other.
If you're still undecided, or both of these pairs are out of your budget, check out our stories on the best noise-cancelling headphones and the best noise-cancelling true wireless earbuds for more top picks in a wide range of prices and designs.
0 notes
Text
AbbVie, Inc. (ABBV) Management Presents at Morgan Stanley 16th Annual Global Healthcare Conference (Transcript)
AbbVie, Inc. (NYSE:ABBV) Morgan Stanley 16th Annual Global Healthcare Conference September 12, 2018 11:40 AM ET
Executives
Bill Chase - Chief Financial Officer
Scott Brun - Head of AbbVie Ventures and VP of Scientific Affairs
Analysts
David Risinger - Morgan Stanley
David Risinger
Okay. So thanks everybody for joining us for the session with AbbVie. I just need to refer you to disclaimers at www.morganstanley.com/researchdisclosures. It’s very much my pleasure to welcome Bill Chase and Scott Brun. So Bill is the Company’s CFO. I’m sure many of you are familiar with him and he’s been in the position for several years and has overseen the Company’s execution of delivering results above expectations for the last several years. Scott is currently Head of AbbVie Ventures and Vice President of Scientific Affairs. He was previously the Head of Pharmaceutical Development and has been instrumental in advancing the Company’s pipeline. So it’s my pleasure to welcome them today. I guess I wanted to start off with a question regarding the execution against your plan.
So, clearly the Company has delivered better than expected performance over a number of years. Investors are skeptical about the longer term given the fear of the biosimilar threats to HUMIRA. So maybe you could sort of tackle it two ways. Talk about the financial targets for 2020 and your confidence in achieving those? And then maybe Scott, you could talk in a bit more detail about the pipeline and its ability to ultimately offset HUMIRA longer term?
Scott Brun
Sure. Well, so David thanks for having us. We always appreciate the opportunity to come out to the Morgan Stanley conference. I think as we start with the big picture and how we’re tracking relative to the long range guidance and particularly in light of that concern around what happens post 2022 when you have an LoE for HUMIRA in the U.S. Like the reality is, since even prior to the spin, this company has been preparing itself for what was going to be in an eventual LoE event around HUMIRA and that was known on day one and our strategy that we said internally and with the board was always trying to build the capabilities and the assets within the Company to be able to negotiate that events and remain a growth vehicle. And at that point in time, we said look our aspirations is to be top tier growth.
Now obviously there's two parts of that equation, one is, what is the HUMIRA curve look like and when, and you've seen us execute very nicely with our legal strategy and the settlements around the U.S. events to delay the onset of LoE in 2022, 2023 time period. The second piece though is what are you going to grow with? And that becomes essentially a pipeline question. And we always knew that we needed to have very, very good differentiated assets. We wanted to be a focus company. We wanted to focus primarily in the areas that we knew that play to our strengths.
So we focus primarily on immunology and oncology. And we set about building what we think is one of the most attractive late stage pipelines in the industry. And we can go through obviously in some detail and Scott's got a lot to say on that thing as well. But at the end of the day, what we called out last time, we updated the strategic plan, isn't if you take HUMIRA out of the mix and you benchmark us back to 2017, which is one of the plan was last updated. We had a business when we looked at our pipeline that we felt was -- we felt comfortable saying was going to grow from about $10 billion in sales size up to $35 billion in 2025.
And the way we're going to do that was through some best in category assets and then which Scott will share with you. Our strong franchise we built in HemOnc with IMBRUVICA and VENCLEXTA products like or at least that we are just underway launching and more recently launched like MAVYRET. And when we look at those assets and we look at the de-risk nature as well as the efficacy and safety that they've shown in a very broad clinical trial, we feel very comfortable that they can get into the market in their respective places and deliver upon those gross projections.
And so we remain very, very confident, pipeline is a huge part of the story. And if you look at our pipeline, not only do we have attractive assets, but this is a very diversified pipeline. We're not delivering all that grows just with one or two assets. There is 5, 6, 7 different aspects at play which we also think is fairly unique when we look at our peers.
David Risinger
Excellent. And maybe Scott, you could add a little bit on and since speak to investors pretty frequently which of the pipeline assets are potentially most underappreciated by investors as you discuss these biggest of pipeline contributors, longer term?
Scott Brun
No, absolutely, I didn't focus on that. Again, David thanks for having us. Bill hit on the number of important themes. When we launched AbbVie, now almost six years ago, focus was incredibly important to make sure that we had the right capabilities from discovery through commercialization market access in a few set areas where we really thought that we could differentiate ourselves with both internally discovered and developed assets as well as externally sourced opportunities. I think that’s been playing out extremely well. I mean I could take the rest of the time going through the qualities of the late-stage pipeline, but maybe I can hit on a few high points.
Certainly, in hematologic malignancies, when you look at it IMBRUVICA and VENCLEXTA, these are two first-in-class agents that are transforming hematologic malignancies of several types. I mean we look at IMBRUVICA the fact is in chronic lymphocytic leukemia, first and second line. It’s really becoming a mainstay of therapy. We've also seen significant results in Waldenstrom's macroglobulinemia. Most recently, we actually had a label update with a study looking in IMBRUVICA combination with Rituxan that again provides us a chemotherapy free option for this particular disease, opportunities in other malignancies like mantle cell lymphoma also tend to build the overall opportunity for IMBRUVICA.
We’re going to continue to progress IMBRUVICA particularly in first line CLL where we think there’s a lot of opportunities in particular in combination with VENCLEXTA first-in-class Bcl-2 inhibitor which have a Phase 2 study captivate to demonstrate the combination of IMBRUVICA and VENCLEXTA can drive to minimal residual disease, essentially no detectable disease by advanced diagnostic methods in 70% to 80% of patients. And so this could really transform the care of CLL away from toxic chemotherapies to a drug combination that could put patients into long-term remission with much less tolerability baggage.
Now talking a little bit more about VENCLEXTA beyond these opportunities in CLL, we’re currently under regulatory review in acute myelogenous leukemia. This is a very devastating rapidly progressive disease that we’ve demonstrated that VENCLEXTA added on to standard-of-care in first line patients who can’t tolerate the harshest chemotherapy can double or triple complete response rates, which led to a breakthrough therapy designation from FDA.
And as I said, current regulatory review that could lead to an approval next year, VENCLEXTA a lot of opportunity in multiple myeloma where we are currently in Phase 3 looking at in combination with Velcade and dexamethasone in second line plus multiple myeloma. We also think there are opportunities in first line myeloma and certain genetically defined population, so a tremendous opportunity is there.
Moving on to our immunology franchise, risankizumab, the partnered assay with BI and anti-IL-23 that has demonstrated some of the highest responses that we’ve seen in patients with psoriasis PASI 100 scores, complete skin clearance on the order of 50% to 60% Superiority versus STELARA, HUMIRA the ability to treat patients who have failed prior TNF inhibitors in a quarterly dosing pattern. And so, risa is currently under regulatory review as well.
Our selective JAK1 inhibitor, upadacitinib, for which we disclosed 5 trials in rheumatoid arthritis. We studied this drug in first line therapy patients who are naive to any treatment, all the way through patients who have failed prior TNF inhibitors. We've lifted Upa with and without methotrexate. We've demonstrated Superiority to HUMIRA. We have over 4,000 patients worth of data. And then every one of these contexts, Upa is performing at the top of the class, certainly directionally, although we have no head-to-head studies directionally better than what we see with baricitinib vs tofacitinib.
I think we've shown from the safety perspective that our rates for venous thromboembolism which has become a point of discussion with this class, really do not differ from placebo and our randomized controlled trials, nor do they worsen overtime, nor do they demonstrate any type of dose response. Certainly, if we want to get into a little bit more of the recent competitive context with recent risa and upa, David during the question we can do that.
ORILISSA, otherwise known as elagolix, the first new therapy for endometriosis related pain in a long time. This disease affects millions of women. They are unsuccessfully treated with combination of oral contraceptives or opioid pain management. We've demonstrated that with this oral therapy that affects the GnRH axis. We can lead to high levels of pain control and do it with a much improved side effect profile relative to show within the nuclear option Lupron.
So, we're in the launch phase of this drug right now. We're in Phase 3 in analysis of bleeding related to uterine fibroid. Another very common gynecological condition where again our two Phase 3 studies that have read out have demonstrated very high levels of efficacy, 75% or so significance of patients had significant reduction in their bleeding.
Again, I could keep going on and on. But I think the point here is as Bill said, diversified assets across a variety of different therapeutic areas that actually have potential beyond these initial indications that I've laid out. And I think as you seen with HUMIRA one of our themes is, to really understand biology and take it to places that it may not have been studied before.
David Risinger
Great. We could just follow up on the competitive landscape…
Scott Brun
We do a couple of announcements over the past year, so…
David Risinger
Yes, could you touch on those?
Scott Brun
Certainly, why don't we go ahead and start with the theme to data and what, I've always got to be careful about talking about someone else who is single study. To sum up what I'll say is based on what we saw from the Phase 2 data in the public domain, I took a Phase 3 data from this first trial or are consistent with that data set?
On the efficacy side both filgotinib and upadacitinib, as I said before directionally appear to provide the potential for improved efficacy relative to baricitinib or tofacitinib. We got to be a careful about our cross-study comparisons here of course especially since we don't know the baseline characteristics of the filgotinib population in total. I would say if you look at the ACR scores, there is puts and takes looking between upa and filgotinib. If you look at some of the DAS scores, which are a high stringent measure of disease control, low disease activity and clinical remission, I can certainly say that, again, all the caveats across study comparisons taking into account that for low dose of upadacitinib is performing every bit as well, if not maybe directionally better than what we see with filgotinib.
So, not seeing clear points of differentiation on the efficacy side, safety is harder to compare because we've got different bits and pieces of what's been shared. I'm glad no patients have venous thromboembolism on the filgotinib trial. But as we know, even patients on background therapy can see VTE. So I think before we can say exactly what that means, we need to see their whole program it's in context. And certainly, we've shared some information on infections, last year so on. I think at this point, it's too early to say that there is any kind of clear signal what differentiation on these low incidence events.
The one thing I do want to point out is that we will be filing an RA with upadacitinib before the end of this year, actually one of the things I must point out, before the end of this year, again, I don't know if Gilead had spoken to their timing when they were just in here. As I understand, the critical path for them is to complete the man-to-male reproductive study to de-risk the 200 milligram dose to see exactly what the benefit risk on that dose is. As I understand that that may put them more than a year behind our current filing timeline.
David Risinger
Got it. That's very helpful. Maybe we could pivot and Bill, you could talk about potential changes in U.S. drug pricing. Obviously, we have to wait and see. And if you could also touch on the notion of rebates going away, it sounds like a pretty big statement. And we'll still need to learn more on what the next steps are from HSS. But it'd be helpful for you to just frame it as you see it currently. And then touch on the rebate issue. Rick had spent a fair amount of time on the 2Q call. So one can refer to that transcript for lots of detail, but still be helpful because it's topic on investors' mind?
Bill Chase
Sure. So look, pricing has been a focus for the industry for the last several years. And it's clear that the administration has made it a focus in these years as well. So we historically whatever we do on our long range plan in the U.S. while we continue to believe the U.S. will remain a price positive environment. We always prudently scale back the rates of increases. So from a long range plan perspective, we've always kind of forecasted because it’s wise to forecast that way that the pricing environment will be getting a little tougher. But beyond the forecast, you've seen actions throughout the industry that have shown the dialogue around price is beginning to have an effect.
So for example, most companies now have moved to one price increase per year. We made a statement couple of years ago that we were doing that. And likewise, price increase is tend to be single digit. We have a statement similar to that as well. And so I think that you are beginning to see an impact through the industry a change in pricing behaviors. And of course, the fall through of those price increases are never in line with list. So I think if you really look at the data right now, you could say on a net-net basis while pricing is still positive in the U.S., it’s probably single-digit fall through, low-single-digit fall through maybe close to medium. But I would say try more like low-single-digits. So it’s clearly having an impact on the industry.
Now, we’re fortunate, we -- our growth is being driven by volume, not by price. If you look at our growth rates this year, they’ve been quite stunning on the top line. Probably last quarter, we had 17% operational growth, I think price overall was about 1% of that. So, when you have new products that are differentiated and you’ve got areas of high unmet need, you can drive impressive top and bottom line performance via volume and that’s what we’ve been doing.
Now, where pricing is going to go from here, little tough to call and obviously we got an initial look at the ideas in the blueprint. But while it was very comprehensive and had some truly creative ideas and we still need to see the details. And so we’re waiting along with the rest of the industry. We haven’t seen major changes to the contracting process to date, because of that. I think it’s kind of, we’re waiting and seeing. Although my guess is, our basic assumption and our long range plan is accurate and pricing will continue to moderate in this market.
In terms of the structural discussion around rebates and the questions that we would need to sort out, I think there’s two really that come to mind. First and foremost is how big, if we move into a paradigm where rebate contracting moves away, right. We move to some other type of contracting. The question is how big of a population of contracts are impacted. The Safe Harbor Provisions directly refers to government business, and the type of contract and that relies on PBM with the government is Medicare. If you look at AbbVie’s U.S. mix about 15% of our business was Medicare.
So, if it just stays within that area, you got 85% of the business in the U.S., which is not impacted. So we need to sort that out and I know some people feel that, it will rapidly move to commercial. We’re not sure, we have to see, how that plays out. That’s an important assumption. But maybe even more important is what rebate contracts are replaced with. We absolutely believe that the government and the market as not going to move away from a scenario, where you can give volume based contracts. It’s kind of a cornerstone of this industry, right. You give contracts based on based on patients under plan, the patient lives under plan and also the ability of that plan to drive compliance via formulary.
And those two things basically add up to a volume based contract. As long as volume based contracting is permitted, we don’t see any reason to believe that it wouldn’t be. It doesn’t really impact our business model. Now, we may need to figure out how you move from a rebate contract to a discount contract. But that’s just, that’s a contract form, it wouldn’t change the overall strategy. So yes, I understand why there’s a lot of concern around this change. But at the end of the day, I think it has less impact on manufacturers then perhaps the PBMs.
David Risinger
That’s extremely helpful. Let me pause there and see if there are any questions before I continue.
Question-and-Answer Session
Q - David Risinger
Okay. So one of the other topics that came up earlier in the year was the co-pay accumulator programs on the part of payers, and obviously, that has some marginal negative impact on reported sales. But could you just recap that and talk about how much of an inflection might be if more payers adopt such accumulators in 2019?
Bill Chase
Yes, sure. So, what we saw play out in the first quarter of 2018 was that there was a significant portion of patients that found themselves on high deductible plans with a co-pay accumulator. That number was roughly 4% to 5% of our commercial business which is about 80%. I'm talking to HUMIRA for example, okay. So if not necessarily not the lion's share, but it's a meaningful portion of patients.
And with this co-pay accumulator, especially did this concept was it ultimately ensured that the patient was on the hook for the full deductible even in the event that the manufacturer was willing to extend a co-pay card. Now, we fundamentally believe one of the issues in healthcare industry is co-pays that patients are burdened with. And so in most cases where we're able to, we offer co-pay assistance in order to alleviate that burden and that out of pocket burden on the consumer, the patient. We think that's absolutely the right thing to do.
What was somewhat perverse about the co-pay accumulators is it essentially could block our ability to do that. And so our view is, it is absolutely a poor contract form. And furthermore, we believe that a lot of people that were in co-pay accumulators may not clearly in plans that had co-pay accumulator, may not clearly understand what the ramifications for those plans were. And we're going to get surprise in the second quarter when they found out that their co-pay assistance have the limited a fixed amount and they now had to pay the deductible. And these deductible could be anywhere at $3,000 or $4,000. So a meaningful hit to your average patient, which in normal course would be covered by co-pay assistance and would not be taxing the patient out of pocket.
So, they get absolutely a horrific insurance form for the patient, it's actually rations their ability to get medications they need. And frankly the medications that we're selling, whether it be HUMIRA or anything else that we've got in our portfolio, these are for life threatening illnesses. And so to basically to private patients of access to that, that therapeutic, based on their ability to pay out of pocket, that was just absolutely the wrong thing to do.
So we recognize that this issue existed, we recognize that a lot of patients might be surprised. It was going to play out in Q2 and Q3 because really frankly, they had to burn through their co-pay cards before they discovered that they're still on the hook for the deductible. And in our Q1 call, we did adjust our HUMIRA guidance number down slightly to account for additional co-pay assistance that we would be able to provide these patients until we were able to sort themselves through this situation.
So, it came up as an issue on our first quarter comp. What I can tell you is it's largely tracking in line with what our expectations were. I think that the measures we've taken have largely been effective. There's been a lot of patient education by patient groups over the nature of these programs. So I like to think that we have wiser patients that will, if to the extent that they can avoid these sorts of insurance constructs in 2019, we certainly think there'll be inclined to do so.
And right now as we forecast '19, we don't see this patient population or the patient population that subject to this form of insurance coverage as expanding dramatically. We think it will largely be contained in a number roughly the size that we're seeing in '18.
David Risinger
Okay that's very helpful. And Scott, maybe we could pivot to IMBRUVICA. So there is an interesting Phase 3 trial in pancreatic cancer that's supporting out soon. Could you just frame that for us?
Scott Brun
Yes, absolutely. David, I mean, again it's better to go back and remind you all the overall strategy when we proceeded with the Pharmacyclics deal. So we felt that, look the foundation of this asset was going to be in the type of hematologic malignancies that I have spoken to particularly CLL. As you progress beyond there, we have increasing levels of risk adjustment that's spoken about some of the other malignancies where we seen great promise. PHOENIX in first line diffuse large B-cell lymphoma didn't measure up the expectations. That's a discrete duration of therapy against difficult effective standard of care, R-CHOP.
But again because of those considerations even the fact that we don't successful there, didn't mitigate our overall expectations for the assay. I would put pancreatic cancer in even another lower bucket with regard to the probability of success that we would apply to that. Obviously, this is a devastating condition for which there exist few good options. And so, we have a Phase 3 trial that is looking at IMBRUVICA added on to paclitaxel gemcitabine. That should be reading out before the end of the year, but again, this is high hurdle, haven't seen the data yet. But certainly, we don't have appropriate expectations for that.
Some of the other trials on IMBRUVICA that will be reading out, well certainly, we talked about CLL and again the iLLUMINATE trial which what's at IMBRUVICA plus GAZYVA versus chlorambucil GAZYVA to continue to enhance our body of data in first line CLL. We top line that and I think maybe able to say more on that at ASH. And then we've got ongoing study that we'll be reading out more in the 2019-2020 timeframe and things like follicular lymphoma first line mantle cell in particular.
David Risinger
Excellent. Well, I think we are out of time. I think we can go on the lot longer, but unfortunately we're out of time. So thank you so much for joining us. Appreciate that.
Source: https://seekingalpha.com/article/4205875-abbvie-inc-abbv-management-presents-morgan-stanley-16th-annual-global-healthcare-conference?source=feed_all_articles
0 notes
Text
Using Python to recover SEO site traffic (Part one)
Helping a client recover from a bad redesign or site migration is probably one of the most critical jobs you can face as an SEO.
The traditional approach of conducting a full forensic SEO audit works well most of the time, but what if there was a way to speed things up? You could potentially save your client a lot of money in opportunity cost.
Last November, I spoke at TechSEO Boost and presented a technique my team and I regularly use to analyze traffic drops. It allows us to pinpoint this painful problem quickly and with surgical precision. As far as I know, there are no tools that currently implement this technique. I coded this solution using Python.
This is the first part of a three-part series. In part two, we will manually group the pages using regular expressions and in part three we will group them automatically using machine learning techniques. Let’s walk over part one and have some fun!
Winners vs losers
Last June we signed up a client that moved from Ecommerce V3 to Shopify and the SEO traffic took a big hit. The owner set up 301 redirects between the old and new sites but made a number of unwise changes like merging a large number of categories and rewriting titles during the move.
When traffic drops, some parts of the site underperform while others don’t. I like to isolate them in order to 1) focus all efforts on the underperforming parts, and 2) learn from the parts that are doing well.
I call this analysis the “Winners vs Losers” analysis. Here, winners are the parts that do well, and losers the ones that do badly.
A visualization of the analysis looks like the chart above. I was able to narrow down the issue to the category pages (Collection pages) and found that the main issue was caused by the site owner merging and eliminating too many categories during the move.
Let’s walk over the steps to put this kind of analysis together in Python.
You can reference my carefully documented Google Colab notebook here.
Getting the data
We want to programmatically compare two separate time frames in Google Analytics (before and after the traffic drop), and we’re going to use the Google Analytics API to do it.
Google Analytics Query Explorer provides the simplest approach to do this in Python.
Head on over to the Google Analytics Query Explorer
Click on the button at the top that says “Click here to Authorize” and follow the steps provided.
Use the dropdown menu to select the website you want to get data from.
Fill in the “metrics” parameter with “ga:newUsers” in order to track new visits.
Complete the “dimensions” parameter with “ga:landingPagePath” in order to get the page URLs.
Fill in the “segment” parameter with “gaid::-5” in order to track organic search visits.
Hit “Run Query” and let it run
Scroll down to the bottom of the page and look for the text box that says “API Query URI.”
Check the box underneath it that says “Include current access_token in the Query URI (will expire in ~60 minutes).”
At the end of the URL in the text box you should now see access_token=string-of-text-here. You will use this string of text in the code snippet below as the variable called token (make sure to paste it inside the quotes)
Now, scroll back up to where we built the query, and look for the parameter that was filled in for you called “ids.” You will use this in the code snippet below as the variable called “gaid.” Again, it should go inside the quotes.
Run the cell once you’ve filled in the gaid and token variables to instantiate them, and we’re good to go!
First, let’s define placeholder variables to pass to the API
metrics = “,”.join([“ga:users”,”ga:newUsers”])
dimensions = “,”.join([“ga:landingPagePath”, “ga:date”])
segment = “gaid::-5”
# Required, please fill in with your own GA information example: ga:23322342
gaid = “ga:23322342”
# Example: string-of-text-here from step 8.2
token = “”
# Example https://www.example.com or http://example.org
base_site_url = “”
# You can change the start and end dates as you like
start = “2017-06-01”
end = “2018-06-30”
The first function combines the placeholder variables we filled in above with an API URL to get Google Analytics data. We make additional API requests and merge them in case the results exceed the 10,000 limit.
def GAData(gaid, start, end, metrics, dimensions,
segment, token, max_results=10000):
“””Creates a generator that yields GA API data
in chunks of size `max_results`”””
#build uri w/ params
api_uri = “https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&”\
“start-date={start}&end-date={end}&metrics={metrics}&”\
“dimensions={dimensions}&segment={segment}&access_token={token}&”\
“max-results={max_results}”
# insert uri params
api_uri = api_uri.format(
gaid=gaid,
start=start,
end=end,
metrics=metrics,
dimensions=dimensions,
segment=segment,
token=token,
max_results=max_results
)
# Using yield to make a generator in an
# attempt to be memory efficient, since data is downloaded in chunks
r = requests.get(api_uri)
data = r.json()
yield data
if data.get(“nextLink”, None):
while data.get(“nextLink”):
new_uri = data.get(“nextLink”)
new_uri += “&access_token={token}”.format(token=token)
r = requests.get(new_uri)
data = r.json()
yield data
In the second function, we load the Google Analytics Query Explorer API response into a pandas DataFrame to simplify our analysis.
import pandas as pd
def to_df(gadata):
“””Takes in a generator from GAData()
creates a dataframe from the rows”””
df = None
for data in gadata:
if df is None:
df = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
else:
newdf = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
df = df.append(newdf)
print(“Gathered {} rows”.format(len(df)))
return df
Now, we can call the functions to load the Google Analytics data.
data = GAData(gaid=gaid, metrics=metrics, start=start,
end=end, dimensions=dimensions, segment=segment,
token=token)
data = to_df(data)
Analyzing the data
Let’s start by just getting a look at the data. We’ll use the .head() method of DataFrames to take a look at the first few rows. Think of this as glancing at only the top few rows of an Excel spreadsheet.
data.head(5)
This displays the first five rows of the data frame.
Most of the data is not in the right format for proper analysis, so let’s perform some data transformations.
First, let’s convert the date to a datetime object and the metrics to numeric values.
data[‘ga:date’] = pd.to_datetime(data[‘ga:date’])
data[‘ga:users’] = pd.to_numeric(data[‘ga:users’])
data[‘ga:newUsers’] = pd.to_numeric(data[‘ga:newUsers’])
Next, we will need the landing page URL, which are relative and include URL parameters in two additional formats: 1) as absolute urls, and 2) as relative paths (without the URL parameters).
from urllib.parse import urlparse, urljoin
data[‘path’] = data[‘ga:landingPagePath’].apply(lambda x: urlparse(x).path)
data[‘url’] = urljoin(base_site_url, data[‘path’])
Now the fun part begins.
The goal of our analysis is to see which pages lost traffic after a particular date–compared to the period before that date–and which gained traffic after that date.
The example date chosen below corresponds to the exact midpoint of our start and end variables used above to gather the data, so that the data both before and after the date is similarly sized.
We begin the analysis by grouping each URL together by their path and adding up the newUsers for each URL. We do this with the built-in pandas method: .groupby(), which takes a column name as an input and groups together each unique value in that column.
The .sum() method then takes the sum of every other column in the data frame within each group.
For more information on these methods please see the Pandas documentation for groupby.
For those who might be familiar with SQL, this is analogous to a GROUP BY clause with a SUM in the select clause
# Change this depending on your needs
MIDPOINT_DATE = “2017-12-15”
before = data[data[‘ga:date’] < pd.to_datetime(MIDPOINT_DATE)]
after = data[data[‘ga:date’] >= pd.to_datetime(MIDPOINT_DATE)]
# Traffic totals before Shopify switch
totals_before = before[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_before = totals_before.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
# Traffic totals after Shopify switch
totals_after = after[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_after = totals_after.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
You can check the totals before and after with this code and double check with the Google Analytics numbers.
print(“Traffic Totals Before: “)
print(“Row count: “, len(totals_before))
print(“Traffic Totals After: “)
print(“Row count: “, len(totals_after))
Next up we merge the two data frames, so that we have a single column corresponding to the URL, and two columns corresponding to the totals before and after the date.
We have different options when merging as illustrated above. Here, we use an “outer” merge, because even if a URL didn’t show up in the “before” period, we still want it to be a part of this merged dataframe. We’ll fill in the blanks with zeros after the merge.
# Comparing pages from before and after the switch
change = totals_after.merge(totals_before,
left_on=”ga:landingPagePath”,
right_on=”ga:landingPagePath”,
suffixes=[“_after”, “_before”],
how=”outer”)
change.fillna(0, inplace=True)
Difference and percentage change
Pandas dataframes make simple calculations on whole columns easy. We can take the difference of two columns and divide two columns and it will perform that operation on every row for us. We will take the difference of the two totals columns, and divide by the “before” column to get the percent change before and after out midpoint date.
Using this percent_change column we can then filter our dataframe to get the winners, the losers and those URLs with no change.
change[‘difference’] = change[‘ga:newUsers_after’] – change[‘ga:newUsers_before’]
change[‘percent_change’] = change[‘difference’] / change[‘ga:newUsers_before’]
winners = change[change[‘percent_change’] > 0]
losers = change[change[‘percent_change’] < 0]
no_change = change[change[‘percent_change’] == 0]
Sanity check
Finally, we do a quick sanity check to make sure that all the traffic from the original data frame is still accounted for after all of our analysis. To do this, we simply take the sum of all traffic for both the original data frame and the two columns of our change dataframe.
# Checking that the total traffic adds up
data[‘ga:newUsers’].sum() == change[[‘ga:newUsers_after’, ‘ga:newUsers_before’]].sum().sum()
It should be True.
Results
Sorting by the difference in our losers data frame, and taking the .head(10), we can see the top 10 losers in our analysis. In other words, these pages lost the most total traffic between the two periods before and after the midpoint date.
losers.sort_values(“difference”).head(10)
You can do the same to review the winners and try to learn from them.
winners.sort_values(“difference”, ascending=False).head(10)
You can export the losing pages to a CSV or Excel using this.
losers.to_csv(“./losing-pages.csv”)
This seems like a lot of work to analyze just one site–and it is!
The magic happens when you reuse this code on new clients and simply need to replace the placeholder variables at the top of the script.
In part two, we will make the output more useful by grouping the losing (and winning) pages by their types to get the chart I included above.
The post Using Python to recover SEO site traffic (Part one) appeared first on Search Engine Watch.
from IM Tips And Tricks https://searchenginewatch.com/2019/02/06/using-python-to-recover-seo-site-traffic-part-one/ from Rising Phoenix SEO https://risingphxseo.tumblr.com/post/182759232745
0 notes
Text
Using Python to recover SEO site traffic (Part one)
Helping a client recover from a bad redesign or site migration is probably one of the most critical jobs you can face as an SEO.
The traditional approach of conducting a full forensic SEO audit works well most of the time, but what if there was a way to speed things up? You could potentially save your client a lot of money in opportunity cost.
Last November, I spoke at TechSEO Boost and presented a technique my team and I regularly use to analyze traffic drops. It allows us to pinpoint this painful problem quickly and with surgical precision. As far as I know, there are no tools that currently implement this technique. I coded this solution using Python.
This is the first part of a three-part series. In part two, we will manually group the pages using regular expressions and in part three we will group them automatically using machine learning techniques. Let’s walk over part one and have some fun!
Winners vs losers
Last June we signed up a client that moved from Ecommerce V3 to Shopify and the SEO traffic took a big hit. The owner set up 301 redirects between the old and new sites but made a number of unwise changes like merging a large number of categories and rewriting titles during the move.
When traffic drops, some parts of the site underperform while others don’t. I like to isolate them in order to 1) focus all efforts on the underperforming parts, and 2) learn from the parts that are doing well.
I call this analysis the “Winners vs Losers” analysis. Here, winners are the parts that do well, and losers the ones that do badly.
A visualization of the analysis looks like the chart above. I was able to narrow down the issue to the category pages (Collection pages) and found that the main issue was caused by the site owner merging and eliminating too many categories during the move.
Let’s walk over the steps to put this kind of analysis together in Python.
You can reference my carefully documented Google Colab notebook here.
Getting the data
We want to programmatically compare two separate time frames in Google Analytics (before and after the traffic drop), and we’re going to use the Google Analytics API to do it.
Google Analytics Query Explorer provides the simplest approach to do this in Python.
Head on over to the Google Analytics Query Explorer
Click on the button at the top that says “Click here to Authorize” and follow the steps provided.
Use the dropdown menu to select the website you want to get data from.
Fill in the “metrics” parameter with “ga:newUsers” in order to track new visits.
Complete the “dimensions” parameter with “ga:landingPagePath” in order to get the page URLs.
Fill in the “segment” parameter with “gaid::-5” in order to track organic search visits.
Hit “Run Query” and let it run
Scroll down to the bottom of the page and look for the text box that says “API Query URI.”
Check the box underneath it that says “Include current access_token in the Query URI (will expire in ~60 minutes).”
At the end of the URL in the text box you should now see access_token=string-of-text-here. You will use this string of text in the code snippet below as the variable called token (make sure to paste it inside the quotes)
Now, scroll back up to where we built the query, and look for the parameter that was filled in for you called “ids.” You will use this in the code snippet below as the variable called “gaid.” Again, it should go inside the quotes.
Run the cell once you’ve filled in the gaid and token variables to instantiate them, and we’re good to go!
First, let’s define placeholder variables to pass to the API
metrics = “,”.join([“ga:users”,”ga:newUsers”])
dimensions = “,”.join([“ga:landingPagePath”, “ga:date”])
segment = “gaid::-5”
# Required, please fill in with your own GA information example: ga:23322342
gaid = “ga:23322342”
# Example: string-of-text-here from step 8.2
token = “”
# Example https://www.example.com or http://example.org
base_site_url = “”
# You can change the start and end dates as you like
start = “2017-06-01”
end = “2018-06-30”
The first function combines the placeholder variables we filled in above with an API URL to get Google Analytics data. We make additional API requests and merge them in case the results exceed the 10,000 limit.
def GAData(gaid, start, end, metrics, dimensions,
segment, token, max_results=10000):
“””Creates a generator that yields GA API data
in chunks of size `max_results`”””
#build uri w/ params
api_uri = “https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&”\
“start-date={start}&end-date={end}&metrics={metrics}&”\
“dimensions={dimensions}&segment={segment}&access_token={token}&”\
“max-results={max_results}”
# insert uri params
api_uri = api_uri.format(
gaid=gaid,
start=start,
end=end,
metrics=metrics,
dimensions=dimensions,
segment=segment,
token=token,
max_results=max_results
)
# Using yield to make a generator in an
# attempt to be memory efficient, since data is downloaded in chunks
r = requests.get(api_uri)
data = r.json()
yield data
if data.get(“nextLink”, None):
while data.get(“nextLink”):
new_uri = data.get(“nextLink”)
new_uri += “&access_token={token}”.format(token=token)
r = requests.get(new_uri)
data = r.json()
yield data
In the second function, we load the Google Analytics Query Explorer API response into a pandas DataFrame to simplify our analysis.
import pandas as pd
def to_df(gadata):
“””Takes in a generator from GAData()
creates a dataframe from the rows”””
df = None
for data in gadata:
if df is None:
df = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
else:
newdf = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
df = df.append(newdf)
print(“Gathered {} rows”.format(len(df)))
return df
Now, we can call the functions to load the Google Analytics data.
data = GAData(gaid=gaid, metrics=metrics, start=start,
end=end, dimensions=dimensions, segment=segment,
token=token)
data = to_df(data)
Analyzing the data
Let’s start by just getting a look at the data. We’ll use the .head() method of DataFrames to take a look at the first few rows. Think of this as glancing at only the top few rows of an Excel spreadsheet.
data.head(5)
This displays the first five rows of the data frame.
Most of the data is not in the right format for proper analysis, so let’s perform some data transformations.
First, let’s convert the date to a datetime object and the metrics to numeric values.
data[‘ga:date’] = pd.to_datetime(data[‘ga:date’])
data[‘ga:users’] = pd.to_numeric(data[‘ga:users’])
data[‘ga:newUsers’] = pd.to_numeric(data[‘ga:newUsers’])
Next, we will need the landing page URL, which are relative and include URL parameters in two additional formats: 1) as absolute urls, and 2) as relative paths (without the URL parameters).
from urllib.parse import urlparse, urljoin
data[‘path’] = data[‘ga:landingPagePath’].apply(lambda x: urlparse(x).path)
data[‘url’] = urljoin(base_site_url, data[‘path’])
Now the fun part begins.
The goal of our analysis is to see which pages lost traffic after a particular date–compared to the period before that date–and which gained traffic after that date.
The example date chosen below corresponds to the exact midpoint of our start and end variables used above to gather the data, so that the data both before and after the date is similarly sized.
We begin the analysis by grouping each URL together by their path and adding up the newUsers for each URL. We do this with the built-in pandas method: .groupby(), which takes a column name as an input and groups together each unique value in that column.
The .sum() method then takes the sum of every other column in the data frame within each group.
For more information on these methods please see the Pandas documentation for groupby.
For those who might be familiar with SQL, this is analogous to a GROUP BY clause with a SUM in the select clause
# Change this depending on your needs
MIDPOINT_DATE = “2017-12-15”
before = data[data[‘ga:date’] < pd.to_datetime(MIDPOINT_DATE)]
after = data[data[‘ga:date’] >= pd.to_datetime(MIDPOINT_DATE)]
# Traffic totals before Shopify switch
totals_before = before[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_before = totals_before.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
# Traffic totals after Shopify switch
totals_after = after[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_after = totals_after.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
You can check the totals before and after with this code and double check with the Google Analytics numbers.
print(“Traffic Totals Before: “)
print(“Row count: “, len(totals_before))
print(“Traffic Totals After: “)
print(“Row count: “, len(totals_after))
Next up we merge the two data frames, so that we have a single column corresponding to the URL, and two columns corresponding to the totals before and after the date.
We have different options when merging as illustrated above. Here, we use an “outer” merge, because even if a URL didn’t show up in the “before” period, we still want it to be a part of this merged dataframe. We’ll fill in the blanks with zeros after the merge.
# Comparing pages from before and after the switch
change = totals_after.merge(totals_before,
left_on=”ga:landingPagePath”,
right_on=”ga:landingPagePath”,
suffixes=[“_after”, “_before”],
how=”outer”)
change.fillna(0, inplace=True)
Difference and percentage change
Pandas dataframes make simple calculations on whole columns easy. We can take the difference of two columns and divide two columns and it will perform that operation on every row for us. We will take the difference of the two totals columns, and divide by the “before” column to get the percent change before and after out midpoint date.
Using this percent_change column we can then filter our dataframe to get the winners, the losers and those URLs with no change.
change[‘difference’] = change[‘ga:newUsers_after’] – change[‘ga:newUsers_before’]
change[‘percent_change’] = change[‘difference’] / change[‘ga:newUsers_before’]
winners = change[change[‘percent_change’] > 0]
losers = change[change[‘percent_change’] < 0]
no_change = change[change[‘percent_change’] == 0]
Sanity check
Finally, we do a quick sanity check to make sure that all the traffic from the original data frame is still accounted for after all of our analysis. To do this, we simply take the sum of all traffic for both the original data frame and the two columns of our change dataframe.
# Checking that the total traffic adds up
data[‘ga:newUsers’].sum() == change[[‘ga:newUsers_after’, ‘ga:newUsers_before’]].sum().sum()
It should be True.
Results
Sorting by the difference in our losers data frame, and taking the .head(10), we can see the top 10 losers in our analysis. In other words, these pages lost the most total traffic between the two periods before and after the midpoint date.
losers.sort_values(“difference”).head(10)
You can do the same to review the winners and try to learn from them.
winners.sort_values(“difference”, ascending=False).head(10)
You can export the losing pages to a CSV or Excel using this.
losers.to_csv(“./losing-pages.csv”)
This seems like a lot of work to analyze just one site–and it is!
The magic happens when you reuse this code on new clients and simply need to replace the placeholder variables at the top of the script.
In part two, we will make the output more useful by grouping the losing (and winning) pages by their types to get the chart I included above.
The post Using Python to recover SEO site traffic (Part one) appeared first on Search Engine Watch.
source https://searchenginewatch.com/2019/02/06/using-python-to-recover-seo-site-traffic-part-one/ from Rising Phoenix SEO http://risingphoenixseo.blogspot.com/2019/02/using-python-to-recover-seo-site.html
0 notes
Text
Using Python to recover SEO site traffic (Part one)
Helping a client recover from a bad redesign or site migration is probably one of the most critical jobs you can face as an SEO.
The traditional approach of conducting a full forensic SEO audit works well most of the time, but what if there was a way to speed things up? You could potentially save your client a lot of money in opportunity cost.
Last November, I spoke at TechSEO Boost and presented a technique my team and I regularly use to analyze traffic drops. It allows us to pinpoint this painful problem quickly and with surgical precision. As far as I know, there are no tools that currently implement this technique. I coded this solution using Python.
This is the first part of a three-part series. In part two, we will manually group the pages using regular expressions and in part three we will group them automatically using machine learning techniques. Let’s walk over part one and have some fun!
Winners vs losers
Last June we signed up a client that moved from Ecommerce V3 to Shopify and the SEO traffic took a big hit. The owner set up 301 redirects between the old and new sites but made a number of unwise changes like merging a large number of categories and rewriting titles during the move.
When traffic drops, some parts of the site underperform while others don’t. I like to isolate them in order to 1) focus all efforts on the underperforming parts, and 2) learn from the parts that are doing well.
I call this analysis the “Winners vs Losers” analysis. Here, winners are the parts that do well, and losers the ones that do badly.
A visualization of the analysis looks like the chart above. I was able to narrow down the issue to the category pages (Collection pages) and found that the main issue was caused by the site owner merging and eliminating too many categories during the move.
Let’s walk over the steps to put this kind of analysis together in Python.
You can reference my carefully documented Google Colab notebook here.
Getting the data
We want to programmatically compare two separate time frames in Google Analytics (before and after the traffic drop), and we’re going to use the Google Analytics API to do it.
Google Analytics Query Explorer provides the simplest approach to do this in Python.
Head on over to the Google Analytics Query Explorer
Click on the button at the top that says “Click here to Authorize” and follow the steps provided.
Use the dropdown menu to select the website you want to get data from.
Fill in the “metrics” parameter with “ga:newUsers” in order to track new visits.
Complete the “dimensions” parameter with “ga:landingPagePath” in order to get the page URLs.
Fill in the “segment” parameter with “gaid::-5” in order to track organic search visits.
Hit “Run Query” and let it run
Scroll down to the bottom of the page and look for the text box that says “API Query URI.”
Check the box underneath it that says “Include current access_token in the Query URI (will expire in ~60 minutes).”
At the end of the URL in the text box you should now see access_token=string-of-text-here. You will use this string of text in the code snippet below as the variable called token (make sure to paste it inside the quotes)
Now, scroll back up to where we built the query, and look for the parameter that was filled in for you called “ids.” You will use this in the code snippet below as the variable called “gaid.” Again, it should go inside the quotes.
Run the cell once you’ve filled in the gaid and token variables to instantiate them, and we’re good to go!
First, let’s define placeholder variables to pass to the API
metrics = “,”.join([“ga:users”,”ga:newUsers”])
dimensions = “,”.join([“ga:landingPagePath”, “ga:date”])
segment = “gaid::-5”
# Required, please fill in with your own GA information example: ga:23322342
gaid = “ga:23322342”
# Example: string-of-text-here from step 8.2
token = “”
# Example https://www.example.com or http://example.org
base_site_url = “”
# You can change the start and end dates as you like
start = “2017-06-01”
end = “2018-06-30”
The first function combines the placeholder variables we filled in above with an API URL to get Google Analytics data. We make additional API requests and merge them in case the results exceed the 10,000 limit.
def GAData(gaid, start, end, metrics, dimensions,
segment, token, max_results=10000):
“””Creates a generator that yields GA API data
in chunks of size `max_results`”””
#build uri w/ params
api_uri = “https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&”\
“start-date={start}&end-date={end}&metrics={metrics}&”\
“dimensions={dimensions}&segment={segment}&access_token={token}&”\
“max-results={max_results}”
# insert uri params
api_uri = api_uri.format(
gaid=gaid,
start=start,
end=end,
metrics=metrics,
dimensions=dimensions,
segment=segment,
token=token,
max_results=max_results
)
# Using yield to make a generator in an
# attempt to be memory efficient, since data is downloaded in chunks
r = requests.get(api_uri)
data = r.json()
yield data
if data.get(“nextLink”, None):
while data.get(“nextLink”):
new_uri = data.get(“nextLink”)
new_uri += “&access_token={token}”.format(token=token)
r = requests.get(new_uri)
data = r.json()
yield data
In the second function, we load the Google Analytics Query Explorer API response into a pandas DataFrame to simplify our analysis.
import pandas as pd
def to_df(gadata):
“””Takes in a generator from GAData()
creates a dataframe from the rows”””
df = None
for data in gadata:
if df is None:
df = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
else:
newdf = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
df = df.append(newdf)
print(“Gathered {} rows”.format(len(df)))
return df
Now, we can call the functions to load the Google Analytics data.
data = GAData(gaid=gaid, metrics=metrics, start=start,
end=end, dimensions=dimensions, segment=segment,
token=token)
data = to_df(data)
Analyzing the data
Let’s start by just getting a look at the data. We’ll use the .head() method of DataFrames to take a look at the first few rows. Think of this as glancing at only the top few rows of an Excel spreadsheet.
data.head(5)
This displays the first five rows of the data frame.
Most of the data is not in the right format for proper analysis, so let’s perform some data transformations.
First, let’s convert the date to a datetime object and the metrics to numeric values.
data[‘ga:date’] = pd.to_datetime(data[‘ga:date’])
data[‘ga:users’] = pd.to_numeric(data[‘ga:users’])
data[‘ga:newUsers’] = pd.to_numeric(data[‘ga:newUsers’])
Next, we will need the landing page URL, which are relative and include URL parameters in two additional formats: 1) as absolute urls, and 2) as relative paths (without the URL parameters).
from urllib.parse import urlparse, urljoin
data[‘path’] = data[‘ga:landingPagePath’].apply(lambda x: urlparse(x).path)
data[‘url’] = urljoin(base_site_url, data[‘path’])
Now the fun part begins.
The goal of our analysis is to see which pages lost traffic after a particular date–compared to the period before that date–and which gained traffic after that date.
The example date chosen below corresponds to the exact midpoint of our start and end variables used above to gather the data, so that the data both before and after the date is similarly sized.
We begin the analysis by grouping each URL together by their path and adding up the newUsers for each URL. We do this with the built-in pandas method: .groupby(), which takes a column name as an input and groups together each unique value in that column.
The .sum() method then takes the sum of every other column in the data frame within each group.
For more information on these methods please see the Pandas documentation for groupby.
For those who might be familiar with SQL, this is analogous to a GROUP BY clause with a SUM in the select clause
# Change this depending on your needs
MIDPOINT_DATE = “2017-12-15”
before = data[data[‘ga:date’] < pd.to_datetime(MIDPOINT_DATE)]
after = data[data[‘ga:date’] >= pd.to_datetime(MIDPOINT_DATE)]
# Traffic totals before Shopify switch
totals_before = before[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_before = totals_before.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
# Traffic totals after Shopify switch
totals_after = after[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_after = totals_after.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
You can check the totals before and after with this code and double check with the Google Analytics numbers.
print(“Traffic Totals Before: “)
print(“Row count: “, len(totals_before))
print(“Traffic Totals After: “)
print(“Row count: “, len(totals_after))
Next up we merge the two data frames, so that we have a single column corresponding to the URL, and two columns corresponding to the totals before and after the date.
We have different options when merging as illustrated above. Here, we use an “outer” merge, because even if a URL didn’t show up in the “before” period, we still want it to be a part of this merged dataframe. We’ll fill in the blanks with zeros after the merge.
# Comparing pages from before and after the switch
change = totals_after.merge(totals_before,
left_on=”ga:landingPagePath”,
right_on=”ga:landingPagePath”,
suffixes=[“_after”, “_before”],
how=”outer”)
change.fillna(0, inplace=True)
Difference and percentage change
Pandas dataframes make simple calculations on whole columns easy. We can take the difference of two columns and divide two columns and it will perform that operation on every row for us. We will take the difference of the two totals columns, and divide by the “before” column to get the percent change before and after out midpoint date.
Using this percent_change column we can then filter our dataframe to get the winners, the losers and those URLs with no change.
change[‘difference’] = change[‘ga:newUsers_after’] – change[‘ga:newUsers_before’]
change[‘percent_change’] = change[‘difference’] / change[‘ga:newUsers_before’]
winners = change[change[‘percent_change’] > 0]
losers = change[change[‘percent_change’] < 0]
no_change = change[change[‘percent_change’] == 0]
Sanity check
Finally, we do a quick sanity check to make sure that all the traffic from the original data frame is still accounted for after all of our analysis. To do this, we simply take the sum of all traffic for both the original data frame and the two columns of our change dataframe.
# Checking that the total traffic adds up
data[‘ga:newUsers’].sum() == change[[‘ga:newUsers_after’, ‘ga:newUsers_before’]].sum().sum()
It should be True.
Results
Sorting by the difference in our losers data frame, and taking the .head(10), we can see the top 10 losers in our analysis. In other words, these pages lost the most total traffic between the two periods before and after the midpoint date.
losers.sort_values(“difference”).head(10)
You can do the same to review the winners and try to learn from them.
winners.sort_values(“difference”, ascending=False).head(10)
You can export the losing pages to a CSV or Excel using this.
losers.to_csv(“./losing-pages.csv”)
This seems like a lot of work to analyze just one site–and it is!
The magic happens when you reuse this code on new clients and simply need to replace the placeholder variables at the top of the script.
In part two, we will make the output more useful by grouping the losing (and winning) pages by their types to get the chart I included above.
The post Using Python to recover SEO site traffic (Part one) appeared first on Search Engine Watch.
from Digtal Marketing News https://searchenginewatch.com/2019/02/06/using-python-to-recover-seo-site-traffic-part-one/
0 notes
Text
Linking Techniques In Depth In Excel
Linking between spreadsheets, workbooks and applications offers huge efficiencies but needs a clear understanding to work accurately and avoid risks that linking can pose.
Understand and apply the power of linking techniques within Excel and other key MS Office applications to boost productivity and efficiency for you and your organization.
Object Linking and Embedding (OLE) makes content that is created in one location or program available in another program.
As an example, in Excel, you can link or reference to other cells in a worksheet or other worksheets, external workbooks, external files, and pages on the internet or your intranet.
Dynamic links ensure changes in source data, graphics, charts, etc. are reflected in all “dependent linked” files. Mastering the linking of information using MS Excel and MS Office is a valuable and marketable skill.
Why Should You Attend
» Use data more efficiently and effectively » Ensure improved data accuracy » Improve job satisfaction, team performance, and professionalism » Impress your management, peers, and clients » Advance all co-workers using MS Office to a consistent standard » Maximize your technology investment performance
Areas Covered
» The link between Excel worksheets and external files » Relative Vs absolute references » Complex formulas linked to external data » Formula Auditing » Update linked values » Change link source » Open a source file » Break links » Link information and graphics between Excel, Access, and other programs » Hyperlink to other workbook cells, external files, and web pages
Who Will Benefit
Any person or organization seeking to significantly boost efficiency, productivity, job satisfaction, and effective use of their technology investment. Particularly personnel in the following fields:
» Accounting » Banking » Business Analysis » Economics » Finance » Insurance » Investment » Management » Statistics » Valuation To Register (or) for more details please click on this below link: https://bit.ly/3s0DIBH/a> Email: [email protected] Tel: (989)341-8773
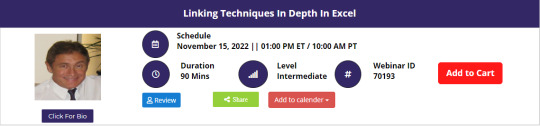
0 notes
Text
Using Python to recover SEO site traffic (Part one)
Helping a client recover from a bad redesign or site migration is probably one of the most critical jobs you can face as an SEO.
The traditional approach of conducting a full forensic SEO audit works well most of the time, but what if there was a way to speed things up? You could potentially save your client a lot of money in opportunity cost.
Last November, I spoke at TechSEO Boost and presented a technique my team and I regularly use to analyze traffic drops. It allows us to pinpoint this painful problem quickly and with surgical precision. As far as I know, there are no tools that currently implement this technique. I coded this solution using Python.
This is the first part of a three-part series. In part two, we will manually group the pages using regular expressions and in part three we will group them automatically using machine learning techniques. Let’s walk over part one and have some fun!
Winners vs losers
Last June we signed up a client that moved from Ecommerce V3 to Shopify and the SEO traffic took a big hit. The owner set up 301 redirects between the old and new sites but made a number of unwise changes like merging a large number of categories and rewriting titles during the move.
When traffic drops, some parts of the site underperform while others don’t. I like to isolate them in order to 1) focus all efforts on the underperforming parts, and 2) learn from the parts that are doing well.
I call this analysis the “Winners vs Losers” analysis. Here, winners are the parts that do well, and losers the ones that do badly.
A visualization of the analysis looks like the chart above. I was able to narrow down the issue to the category pages (Collection pages) and found that the main issue was caused by the site owner merging and eliminating too many categories during the move.
Let’s walk over the steps to put this kind of analysis together in Python.
You can reference my carefully documented Google Colab notebook here.
Getting the data
We want to programmatically compare two separate time frames in Google Analytics (before and after the traffic drop), and we’re going to use the Google Analytics API to do it.
Google Analytics Query Explorer provides the simplest approach to do this in Python.
Head on over to the Google Analytics Query Explorer
Click on the button at the top that says “Click here to Authorize” and follow the steps provided.
Use the dropdown menu to select the website you want to get data from.
Fill in the “metrics” parameter with “ga:newUsers” in order to track new visits.
Complete the “dimensions” parameter with “ga:landingPagePath” in order to get the page URLs.
Fill in the “segment” parameter with “gaid::-5” in order to track organic search visits.
Hit “Run Query” and let it run
Scroll down to the bottom of the page and look for the text box that says “API Query URI.”
Check the box underneath it that says “Include current access_token in the Query URI (will expire in ~60 minutes).”
At the end of the URL in the text box you should now see access_token=string-of-text-here. You will use this string of text in the code snippet below as the variable called token (make sure to paste it inside the quotes)
Now, scroll back up to where we built the query, and look for the parameter that was filled in for you called “ids.” You will use this in the code snippet below as the variable called “gaid.” Again, it should go inside the quotes.
Run the cell once you’ve filled in the gaid and token variables to instantiate them, and we’re good to go!
First, let’s define placeholder variables to pass to the API
metrics = “,”.join([“ga:users”,”ga:newUsers”])
dimensions = “,”.join([“ga:landingPagePath”, “ga:date”])
segment = “gaid::-5”
# Required, please fill in with your own GA information example: ga:23322342
gaid = “ga:23322342”
# Example: string-of-text-here from step 8.2
token = “”
# Example https://www.example.com or http://example.org
base_site_url = “”
# You can change the start and end dates as you like
start = “2017-06-01”
end = “2018-06-30”
The first function combines the placeholder variables we filled in above with an API URL to get Google Analytics data. We make additional API requests and merge them in case the results exceed the 10,000 limit.
def GAData(gaid, start, end, metrics, dimensions,
segment, token, max_results=10000):
“””Creates a generator that yields GA API data
in chunks of size `max_results`”””
#build uri w/ params
api_uri = “https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&”\
“start-date={start}&end-date={end}&metrics={metrics}&”\
“dimensions={dimensions}&segment={segment}&access_token={token}&”\
“max-results={max_results}”
# insert uri params
api_uri = api_uri.format(
gaid=gaid,
start=start,
end=end,
metrics=metrics,
dimensions=dimensions,
segment=segment,
token=token,
max_results=max_results
)
# Using yield to make a generator in an
# attempt to be memory efficient, since data is downloaded in chunks
r = requests.get(api_uri)
data = r.json()
yield data
if data.get(“nextLink”, None):
while data.get(“nextLink”):
new_uri = data.get(“nextLink”)
new_uri += “&access_token={token}”.format(token=token)
r = requests.get(new_uri)
data = r.json()
yield data
In the second function, we load the Google Analytics Query Explorer API response into a pandas DataFrame to simplify our analysis.
import pandas as pd
def to_df(gadata):
“””Takes in a generator from GAData()
creates a dataframe from the rows”””
df = None
for data in gadata:
if df is None:
df = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
else:
newdf = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
df = df.append(newdf)
print(“Gathered {} rows”.format(len(df)))
return df
Now, we can call the functions to load the Google Analytics data.
data = GAData(gaid=gaid, metrics=metrics, start=start,
end=end, dimensions=dimensions, segment=segment,
token=token)
data = to_df(data)
Analyzing the data
Let’s start by just getting a look at the data. We’ll use the .head() method of DataFrames to take a look at the first few rows. Think of this as glancing at only the top few rows of an Excel spreadsheet.
data.head(5)
This displays the first five rows of the data frame.
Most of the data is not in the right format for proper analysis, so let’s perform some data transformations.
First, let’s convert the date to a datetime object and the metrics to numeric values.
data[‘ga:date’] = pd.to_datetime(data[‘ga:date’])
data[‘ga:users’] = pd.to_numeric(data[‘ga:users’])
data[‘ga:newUsers’] = pd.to_numeric(data[‘ga:newUsers’])
Next, we will need the landing page URL, which are relative and include URL parameters in two additional formats: 1) as absolute urls, and 2) as relative paths (without the URL parameters).
from urllib.parse import urlparse, urljoin
data[‘path’] = data[‘ga:landingPagePath’].apply(lambda x: urlparse(x).path)
data[‘url’] = urljoin(base_site_url, data[‘path’])
Now the fun part begins.
The goal of our analysis is to see which pages lost traffic after a particular date–compared to the period before that date–and which gained traffic after that date.
The example date chosen below corresponds to the exact midpoint of our start and end variables used above to gather the data, so that the data both before and after the date is similarly sized.
We begin the analysis by grouping each URL together by their path and adding up the newUsers for each URL. We do this with the built-in pandas method: .groupby(), which takes a column name as an input and groups together each unique value in that column.
The .sum() method then takes the sum of every other column in the data frame within each group.
For more information on these methods please see the Pandas documentation for groupby.
For those who might be familiar with SQL, this is analogous to a GROUP BY clause with a SUM in the select clause
# Change this depending on your needs
MIDPOINT_DATE = “2017-12-15”
before = data[data[‘ga:date’] < pd.to_datetime(MIDPOINT_DATE)]
after = data[data[‘ga:date’] >= pd.to_datetime(MIDPOINT_DATE)]
# Traffic totals before Shopify switch
totals_before = before[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_before = totals_before.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
# Traffic totals after Shopify switch
totals_after = after[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_after = totals_after.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
You can check the totals before and after with this code and double check with the Google Analytics numbers.
print(“Traffic Totals Before: “)
print(“Row count: “, len(totals_before))
print(“Traffic Totals After: “)
print(“Row count: “, len(totals_after))
Next up we merge the two data frames, so that we have a single column corresponding to the URL, and two columns corresponding to the totals before and after the date.
We have different options when merging as illustrated above. Here, we use an “outer” merge, because even if a URL didn’t show up in the “before” period, we still want it to be a part of this merged dataframe. We’ll fill in the blanks with zeros after the merge.
# Comparing pages from before and after the switch
change = totals_after.merge(totals_before,
left_on=”ga:landingPagePath”,
right_on=”ga:landingPagePath”,
suffixes=[“_after”, “_before”],
how=”outer”)
change.fillna(0, inplace=True)
Difference and percentage change
Pandas dataframes make simple calculations on whole columns easy. We can take the difference of two columns and divide two columns and it will perform that operation on every row for us. We will take the difference of the two totals columns, and divide by the “before” column to get the percent change before and after out midpoint date.
Using this percent_change column we can then filter our dataframe to get the winners, the losers and those URLs with no change.
change[‘difference’] = change[‘ga:newUsers_after’] – change[‘ga:newUsers_before’]
change[‘percent_change’] = change[‘difference’] / change[‘ga:newUsers_before’]
winners = change[change[‘percent_change’] > 0]
losers = change[change[‘percent_change’] < 0]
no_change = change[change[‘percent_change’] == 0]
Sanity check
Finally, we do a quick sanity check to make sure that all the traffic from the original data frame is still accounted for after all of our analysis. To do this, we simply take the sum of all traffic for both the original data frame and the two columns of our change dataframe.
# Checking that the total traffic adds up
data[‘ga:newUsers’].sum() == change[[‘ga:newUsers_after’, ‘ga:newUsers_before’]].sum().sum()
It should be True.
Results
Sorting by the difference in our losers data frame, and taking the .head(10), we can see the top 10 losers in our analysis. In other words, these pages lost the most total traffic between the two periods before and after the midpoint date.
losers.sort_values(“difference”).head(10)
You can do the same to review the winners and try to learn from them.
winners.sort_values(“difference”, ascending=False).head(10)
You can export the losing pages to a CSV or Excel using this.
losers.to_csv(“./losing-pages.csv”)
This seems like a lot of work to analyze just one site–and it is!
The magic happens when you reuse this code on new clients and simply need to replace the placeholder variables at the top of the script.
In part two, we will make the output more useful by grouping the losing (and winning) pages by their types to get the chart I included above.
The post Using Python to recover SEO site traffic (Part one) appeared first on Search Engine Watch.
from Digtal Marketing News https://searchenginewatch.com/2019/02/06/using-python-to-recover-seo-site-traffic-part-one/
0 notes
Text
Using Python to recover SEO site traffic (Part one)
Helping a client recover from a bad redesign or site migration is probably one of the most critical jobs you can face as an SEO.
The traditional approach of conducting a full forensic SEO audit works well most of the time, but what if there was a way to speed things up? You could potentially save your client a lot of money in opportunity cost.
Last November, I spoke at TechSEO Boost and presented a technique my team and I regularly use to analyze traffic drops. It allows us to pinpoint this painful problem quickly and with surgical precision. As far as I know, there are no tools that currently implement this technique. I coded this solution using Python.
This is the first part of a three-part series. In part two, we will manually group the pages using regular expressions and in part three we will group them automatically using machine learning techniques. Let’s walk over part one and have some fun!
Winners vs losers
Last June we signed up a client that moved from Ecommerce V3 to Shopify and the SEO traffic took a big hit. The owner set up 301 redirects between the old and new sites but made a number of unwise changes like merging a large number of categories and rewriting titles during the move.
When traffic drops, some parts of the site underperform while others don’t. I like to isolate them in order to 1) focus all efforts on the underperforming parts, and 2) learn from the parts that are doing well.
I call this analysis the “Winners vs Losers” analysis. Here, winners are the parts that do well, and losers the ones that do badly.
A visualization of the analysis looks like the chart above. I was able to narrow down the issue to the category pages (Collection pages) and found that the main issue was caused by the site owner merging and eliminating too many categories during the move.
Let’s walk over the steps to put this kind of analysis together in Python.
You can reference my carefully documented Google Colab notebook here.
Getting the data
We want to programmatically compare two separate time frames in Google Analytics (before and after the traffic drop), and we’re going to use the Google Analytics API to do it.
Google Analytics Query Explorer provides the simplest approach to do this in Python.
Head on over to the Google Analytics Query Explorer
Click on the button at the top that says “Click here to Authorize” and follow the steps provided.
Use the dropdown menu to select the website you want to get data from.
Fill in the “metrics” parameter with “ga:newUsers” in order to track new visits.
Complete the “dimensions” parameter with “ga:landingPagePath” in order to get the page URLs.
Fill in the “segment” parameter with “gaid::-5” in order to track organic search visits.
Hit “Run Query” and let it run
Scroll down to the bottom of the page and look for the text box that says “API Query URI.”
Check the box underneath it that says “Include current access_token in the Query URI (will expire in ~60 minutes).”
At the end of the URL in the text box you should now see access_token=string-of-text-here. You will use this string of text in the code snippet below as the variable called token (make sure to paste it inside the quotes)
Now, scroll back up to where we built the query, and look for the parameter that was filled in for you called “ids.” You will use this in the code snippet below as the variable called “gaid.” Again, it should go inside the quotes.
Run the cell once you’ve filled in the gaid and token variables to instantiate them, and we’re good to go!
First, let’s define placeholder variables to pass to the API
metrics = “,”.join([“ga:users”,”ga:newUsers”])
dimensions = “,”.join([“ga:landingPagePath”, “ga:date”])
segment = “gaid::-5”
# Required, please fill in with your own GA information example: ga:23322342
gaid = “ga:23322342”
# Example: string-of-text-here from step 8.2
token = “”
# Example https://www.example.com or http://example.org
base_site_url = “”
# You can change the start and end dates as you like
start = “2017-06-01”
end = “2018-06-30”
The first function combines the placeholder variables we filled in above with an API URL to get Google Analytics data. We make additional API requests and merge them in case the results exceed the 10,000 limit.
def GAData(gaid, start, end, metrics, dimensions,
segment, token, max_results=10000):
“””Creates a generator that yields GA API data
in chunks of size `max_results`”””
#build uri w/ params
api_uri = “https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&”\
“start-date={start}&end-date={end}&metrics={metrics}&”\
“dimensions={dimensions}&segment={segment}&access_token={token}&”\
“max-results={max_results}”
# insert uri params
api_uri = api_uri.format(
gaid=gaid,
start=start,
end=end,
metrics=metrics,
dimensions=dimensions,
segment=segment,
token=token,
max_results=max_results
)
# Using yield to make a generator in an
# attempt to be memory efficient, since data is downloaded in chunks
r = requests.get(api_uri)
data = r.json()
yield data
if data.get(“nextLink”, None):
while data.get(“nextLink”):
new_uri = data.get(“nextLink”)
new_uri += “&access_token={token}”.format(token=token)
r = requests.get(new_uri)
data = r.json()
yield data
In the second function, we load the Google Analytics Query Explorer API response into a pandas DataFrame to simplify our analysis.
import pandas as pd
def to_df(gadata):
“””Takes in a generator from GAData()
creates a dataframe from the rows”””
df = None
for data in gadata:
if df is None:
df = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
else:
newdf = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
df = df.append(newdf)
print(“Gathered {} rows”.format(len(df)))
return df
Now, we can call the functions to load the Google Analytics data.
data = GAData(gaid=gaid, metrics=metrics, start=start,
end=end, dimensions=dimensions, segment=segment,
token=token)
data = to_df(data)
Analyzing the data
Let’s start by just getting a look at the data. We’ll use the .head() method of DataFrames to take a look at the first few rows. Think of this as glancing at only the top few rows of an Excel spreadsheet.
data.head(5)
This displays the first five rows of the data frame.
Most of the data is not in the right format for proper analysis, so let’s perform some data transformations.
First, let’s convert the date to a datetime object and the metrics to numeric values.
data[‘ga:date’] = pd.to_datetime(data[‘ga:date’])
data[‘ga:users’] = pd.to_numeric(data[‘ga:users’])
data[‘ga:newUsers’] = pd.to_numeric(data[‘ga:newUsers’])
Next, we will need the landing page URL, which are relative and include URL parameters in two additional formats: 1) as absolute urls, and 2) as relative paths (without the URL parameters).
from urllib.parse import urlparse, urljoin
data[‘path’] = data[‘ga:landingPagePath’].apply(lambda x: urlparse(x).path)
data[‘url’] = urljoin(base_site_url, data[‘path’])
Now the fun part begins.
The goal of our analysis is to see which pages lost traffic after a particular date–compared to the period before that date–and which gained traffic after that date.
The example date chosen below corresponds to the exact midpoint of our start and end variables used above to gather the data, so that the data both before and after the date is similarly sized.
We begin the analysis by grouping each URL together by their path and adding up the newUsers for each URL. We do this with the built-in pandas method: .groupby(), which takes a column name as an input and groups together each unique value in that column.
The .sum() method then takes the sum of every other column in the data frame within each group.
For more information on these methods please see the Pandas documentation for groupby.
For those who might be familiar with SQL, this is analogous to a GROUP BY clause with a SUM in the select clause
# Change this depending on your needs
MIDPOINT_DATE = “2017-12-15”
before = data[data[‘ga:date’] < pd.to_datetime(MIDPOINT_DATE)]
after = data[data[‘ga:date’] >= pd.to_datetime(MIDPOINT_DATE)]
# Traffic totals before Shopify switch
totals_before = before[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_before = totals_before.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
# Traffic totals after Shopify switch
totals_after = after[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_after = totals_after.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
You can check the totals before and after with this code and double check with the Google Analytics numbers.
print(“Traffic Totals Before: “)
print(“Row count: “, len(totals_before))
print(“Traffic Totals After: “)
print(“Row count: “, len(totals_after))
Next up we merge the two data frames, so that we have a single column corresponding to the URL, and two columns corresponding to the totals before and after the date.
We have different options when merging as illustrated above. Here, we use an “outer” merge, because even if a URL didn’t show up in the “before” period, we still want it to be a part of this merged dataframe. We’ll fill in the blanks with zeros after the merge.
# Comparing pages from before and after the switch
change = totals_after.merge(totals_before,
left_on=”ga:landingPagePath”,
right_on=”ga:landingPagePath”,
suffixes=[“_after”, “_before”],
how=”outer”)
change.fillna(0, inplace=True)
Difference and percentage change
Pandas dataframes make simple calculations on whole columns easy. We can take the difference of two columns and divide two columns and it will perform that operation on every row for us. We will take the difference of the two totals columns, and divide by the “before” column to get the percent change before and after out midpoint date.
Using this percent_change column we can then filter our dataframe to get the winners, the losers and those URLs with no change.
change[‘difference’] = change[‘ga:newUsers_after’] – change[‘ga:newUsers_before’]
change[‘percent_change’] = change[‘difference’] / change[‘ga:newUsers_before’]
winners = change[change[‘percent_change’] > 0]
losers = change[change[‘percent_change’] < 0]
no_change = change[change[‘percent_change’] == 0]
Sanity check
Finally, we do a quick sanity check to make sure that all the traffic from the original data frame is still accounted for after all of our analysis. To do this, we simply take the sum of all traffic for both the original data frame and the two columns of our change dataframe.
# Checking that the total traffic adds up
data[‘ga:newUsers’].sum() == change[[‘ga:newUsers_after’, ‘ga:newUsers_before’]].sum().sum()
It should be True.
Results
Sorting by the difference in our losers data frame, and taking the .head(10), we can see the top 10 losers in our analysis. In other words, these pages lost the most total traffic between the two periods before and after the midpoint date.
losers.sort_values(“difference”).head(10)
You can do the same to review the winners and try to learn from them.
winners.sort_values(“difference”, ascending=False).head(10)
You can export the losing pages to a CSV or Excel using this.
losers.to_csv(“./losing-pages.csv”)
This seems like a lot of work to analyze just one site–and it is!
The magic happens when you reuse this code on new clients and simply need to replace the placeholder variables at the top of the script.
In part two, we will make the output more useful by grouping the losing (and winning) pages by their types to get the chart I included above.
The post Using Python to recover SEO site traffic (Part one) appeared first on Search Engine Watch.
from Digtal Marketing News https://searchenginewatch.com/2019/02/06/using-python-to-recover-seo-site-traffic-part-one/
0 notes
Text
Using Python to recover SEO site traffic (Part one)
Helping a client recover from a bad redesign or site migration is probably one of the most critical jobs you can face as an SEO.
The traditional approach of conducting a full forensic SEO audit works well most of the time, but what if there was a way to speed things up? You could potentially save your client a lot of money in opportunity cost.
Last November, I spoke at TechSEO Boost and presented a technique my team and I regularly use to analyze traffic drops. It allows us to pinpoint this painful problem quickly and with surgical precision. As far as I know, there are no tools that currently implement this technique. I coded this solution using Python.
This is the first part of a three-part series. In part two, we will manually group the pages using regular expressions and in part three we will group them automatically using machine learning techniques. Let’s walk over part one and have some fun!
Winners vs losers
Last June we signed up a client that moved from Ecommerce V3 to Shopify and the SEO traffic took a big hit. The owner set up 301 redirects between the old and new sites but made a number of unwise changes like merging a large number of categories and rewriting titles during the move.
When traffic drops, some parts of the site underperform while others don’t. I like to isolate them in order to 1) focus all efforts on the underperforming parts, and 2) learn from the parts that are doing well.
I call this analysis the “Winners vs Losers” analysis. Here, winners are the parts that do well, and losers the ones that do badly.
A visualization of the analysis looks like the chart above. I was able to narrow down the issue to the category pages (Collection pages) and found that the main issue was caused by the site owner merging and eliminating too many categories during the move.
Let’s walk over the steps to put this kind of analysis together in Python.
You can reference my carefully documented Google Colab notebook here.
Getting the data
We want to programmatically compare two separate time frames in Google Analytics (before and after the traffic drop), and we’re going to use the Google Analytics API to do it.
Google Analytics Query Explorer provides the simplest approach to do this in Python.
Head on over to the Google Analytics Query Explorer
Click on the button at the top that says “Click here to Authorize” and follow the steps provided.
Use the dropdown menu to select the website you want to get data from.
Fill in the “metrics” parameter with “ga:newUsers” in order to track new visits.
Complete the “dimensions” parameter with “ga:landingPagePath” in order to get the page URLs.
Fill in the “segment” parameter with “gaid::-5” in order to track organic search visits.
Hit “Run Query” and let it run
Scroll down to the bottom of the page and look for the text box that says “API Query URI.”
Check the box underneath it that says “Include current access_token in the Query URI (will expire in ~60 minutes).”
At the end of the URL in the text box you should now see access_token=string-of-text-here. You will use this string of text in the code snippet below as the variable called token (make sure to paste it inside the quotes)
Now, scroll back up to where we built the query, and look for the parameter that was filled in for you called “ids.” You will use this in the code snippet below as the variable called “gaid.” Again, it should go inside the quotes.
Run the cell once you’ve filled in the gaid and token variables to instantiate them, and we’re good to go!
First, let’s define placeholder variables to pass to the API
metrics = “,”.join([“ga:users”,”ga:newUsers”])
dimensions = “,”.join([“ga:landingPagePath”, “ga:date”])
segment = “gaid::-5”
# Required, please fill in with your own GA information example: ga:23322342
gaid = “ga:23322342”
# Example: string-of-text-here from step 8.2
token = “”
# Example https://www.example.com or http://example.org
base_site_url = “”
# You can change the start and end dates as you like
start = “2017-06-01”
end = “2018-06-30”
The first function combines the placeholder variables we filled in above with an API URL to get Google Analytics data. We make additional API requests and merge them in case the results exceed the 10,000 limit.
def GAData(gaid, start, end, metrics, dimensions,
segment, token, max_results=10000):
“””Creates a generator that yields GA API data
in chunks of size `max_results`”””
#build uri w/ params
api_uri = “https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&”\
“start-date={start}&end-date={end}&metrics={metrics}&”\
“dimensions={dimensions}&segment={segment}&access_token={token}&”\
“max-results={max_results}”
# insert uri params
api_uri = api_uri.format(
gaid=gaid,
start=start,
end=end,
metrics=metrics,
dimensions=dimensions,
segment=segment,
token=token,
max_results=max_results
)
# Using yield to make a generator in an
# attempt to be memory efficient, since data is downloaded in chunks
r = requests.get(api_uri)
data = r.json()
yield data
if data.get(“nextLink”, None):
while data.get(“nextLink”):
new_uri = data.get(“nextLink”)
new_uri += “&access_token={token}”.format(token=token)
r = requests.get(new_uri)
data = r.json()
yield data
In the second function, we load the Google Analytics Query Explorer API response into a pandas DataFrame to simplify our analysis.
import pandas as pd
def to_df(gadata):
“””Takes in a generator from GAData()
creates a dataframe from the rows”””
df = None
for data in gadata:
if df is None:
df = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
else:
newdf = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
df = df.append(newdf)
print(“Gathered {} rows”.format(len(df)))
return df
Now, we can call the functions to load the Google Analytics data.
data = GAData(gaid=gaid, metrics=metrics, start=start,
end=end, dimensions=dimensions, segment=segment,
token=token)
data = to_df(data)
Analyzing the data
Let’s start by just getting a look at the data. We’ll use the .head() method of DataFrames to take a look at the first few rows. Think of this as glancing at only the top few rows of an Excel spreadsheet.
data.head(5)
This displays the first five rows of the data frame.
Most of the data is not in the right format for proper analysis, so let’s perform some data transformations.
First, let’s convert the date to a datetime object and the metrics to numeric values.
data[‘ga:date’] = pd.to_datetime(data[‘ga:date’])
data[‘ga:users’] = pd.to_numeric(data[‘ga:users’])
data[‘ga:newUsers’] = pd.to_numeric(data[‘ga:newUsers’])
Next, we will need the landing page URL, which are relative and include URL parameters in two additional formats: 1) as absolute urls, and 2) as relative paths (without the URL parameters).
from urllib.parse import urlparse, urljoin
data[‘path’] = data[‘ga:landingPagePath’].apply(lambda x: urlparse(x).path)
data[‘url’] = urljoin(base_site_url, data[‘path’])
Now the fun part begins.
The goal of our analysis is to see which pages lost traffic after a particular date–compared to the period before that date–and which gained traffic after that date.
The example date chosen below corresponds to the exact midpoint of our start and end variables used above to gather the data, so that the data both before and after the date is similarly sized.
We begin the analysis by grouping each URL together by their path and adding up the newUsers for each URL. We do this with the built-in pandas method: .groupby(), which takes a column name as an input and groups together each unique value in that column.
The .sum() method then takes the sum of every other column in the data frame within each group.
For more information on these methods please see the Pandas documentation for groupby.
For those who might be familiar with SQL, this is analogous to a GROUP BY clause with a SUM in the select clause
# Change this depending on your needs
MIDPOINT_DATE = “2017-12-15”
before = data[data[‘ga:date’] < pd.to_datetime(MIDPOINT_DATE)]
after = data[data[‘ga:date’] >= pd.to_datetime(MIDPOINT_DATE)]
# Traffic totals before Shopify switch
totals_before = before[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_before = totals_before.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
# Traffic totals after Shopify switch
totals_after = after[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_after = totals_after.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
You can check the totals before and after with this code and double check with the Google Analytics numbers.
print(“Traffic Totals Before: “)
print(“Row count: “, len(totals_before))
print(“Traffic Totals After: “)
print(“Row count: “, len(totals_after))
Next up we merge the two data frames, so that we have a single column corresponding to the URL, and two columns corresponding to the totals before and after the date.
We have different options when merging as illustrated above. Here, we use an “outer” merge, because even if a URL didn’t show up in the “before” period, we still want it to be a part of this merged dataframe. We’ll fill in the blanks with zeros after the merge.
# Comparing pages from before and after the switch
change = totals_after.merge(totals_before,
left_on=”ga:landingPagePath”,
right_on=”ga:landingPagePath”,
suffixes=[“_after”, “_before”],
how=”outer”)
change.fillna(0, inplace=True)
Difference and percentage change
Pandas dataframes make simple calculations on whole columns easy. We can take the difference of two columns and divide two columns and it will perform that operation on every row for us. We will take the difference of the two totals columns, and divide by the “before” column to get the percent change before and after out midpoint date.
Using this percent_change column we can then filter our dataframe to get the winners, the losers and those URLs with no change.
change[‘difference’] = change[‘ga:newUsers_after’] – change[‘ga:newUsers_before’]
change[‘percent_change’] = change[‘difference’] / change[‘ga:newUsers_before’]
winners = change[change[‘percent_change’] > 0]
losers = change[change[‘percent_change’] < 0]
no_change = change[change[‘percent_change’] == 0]
Sanity check
Finally, we do a quick sanity check to make sure that all the traffic from the original data frame is still accounted for after all of our analysis. To do this, we simply take the sum of all traffic for both the original data frame and the two columns of our change dataframe.
# Checking that the total traffic adds up
data[‘ga:newUsers’].sum() == change[[‘ga:newUsers_after’, ‘ga:newUsers_before’]].sum().sum()
It should be True.
Results
Sorting by the difference in our losers data frame, and taking the .head(10), we can see the top 10 losers in our analysis. In other words, these pages lost the most total traffic between the two periods before and after the midpoint date.
losers.sort_values(“difference”).head(10)
You can do the same to review the winners and try to learn from them.
winners.sort_values(“difference”, ascending=False).head(10)
You can export the losing pages to a CSV or Excel using this.
losers.to_csv(“./losing-pages.csv”)
This seems like a lot of work to analyze just one site–and it is!
The magic happens when you reuse this code on new clients and simply need to replace the placeholder variables at the top of the script.
In part two, we will make the output more useful by grouping the losing (and winning) pages by their types to get the chart I included above.
The post Using Python to recover SEO site traffic (Part one) appeared first on Search Engine Watch.
from Digtal Marketing News https://searchenginewatch.com/2019/02/06/using-python-to-recover-seo-site-traffic-part-one/
0 notes
Text
Using Python to recover SEO site traffic (Part one)
Helping a client recover from a bad redesign or site migration is probably one of the most critical jobs you can face as an SEO.
The traditional approach of conducting a full forensic SEO audit works well most of the time, but what if there was a way to speed things up? You could potentially save your client a lot of money in opportunity cost.
Last November, I spoke at TechSEO Boost and presented a technique my team and I regularly use to analyze traffic drops. It allows us to pinpoint this painful problem quickly and with surgical precision. As far as I know, there are no tools that currently implement this technique. I coded this solution using Python.
This is the first part of a three-part series. In part two, we will manually group the pages using regular expressions and in part three we will group them automatically using machine learning techniques. Let’s walk over part one and have some fun!
Winners vs losers
Last June we signed up a client that moved from Ecommerce V3 to Shopify and the SEO traffic took a big hit. The owner set up 301 redirects between the old and new sites but made a number of unwise changes like merging a large number of categories and rewriting titles during the move.
When traffic drops, some parts of the site underperform while others don’t. I like to isolate them in order to 1) focus all efforts on the underperforming parts, and 2) learn from the parts that are doing well.
I call this analysis the “Winners vs Losers” analysis. Here, winners are the parts that do well, and losers the ones that do badly.
A visualization of the analysis looks like the chart above. I was able to narrow down the issue to the category pages (Collection pages) and found that the main issue was caused by the site owner merging and eliminating too many categories during the move.
Let’s walk over the steps to put this kind of analysis together in Python.
You can reference my carefully documented Google Colab notebook here.
Getting the data
We want to programmatically compare two separate time frames in Google Analytics (before and after the traffic drop), and we’re going to use the Google Analytics API to do it.
Google Analytics Query Explorer provides the simplest approach to do this in Python.
Head on over to the Google Analytics Query Explorer
Click on the button at the top that says “Click here to Authorize” and follow the steps provided.
Use the dropdown menu to select the website you want to get data from.
Fill in the “metrics” parameter with “ga:newUsers” in order to track new visits.
Complete the “dimensions” parameter with “ga:landingPagePath” in order to get the page URLs.
Fill in the “segment” parameter with “gaid::-5” in order to track organic search visits.
Hit “Run Query” and let it run
Scroll down to the bottom of the page and look for the text box that says “API Query URI.”
Check the box underneath it that says “Include current access_token in the Query URI (will expire in ~60 minutes).”
At the end of the URL in the text box you should now see access_token=string-of-text-here. You will use this string of text in the code snippet below as the variable called token (make sure to paste it inside the quotes)
Now, scroll back up to where we built the query, and look for the parameter that was filled in for you called “ids.” You will use this in the code snippet below as the variable called “gaid.” Again, it should go inside the quotes.
Run the cell once you’ve filled in the gaid and token variables to instantiate them, and we’re good to go!
First, let’s define placeholder variables to pass to the API
metrics = “,”.join([“ga:users”,”ga:newUsers”])
dimensions = “,”.join([“ga:landingPagePath”, “ga:date”])
segment = “gaid::-5”
# Required, please fill in with your own GA information example: ga:23322342
gaid = “ga:23322342”
# Example: string-of-text-here from step 8.2
token = “”
# Example https://www.example.com or http://example.org
base_site_url = “”
# You can change the start and end dates as you like
start = “2017-06-01”
end = “2018-06-30”
The first function combines the placeholder variables we filled in above with an API URL to get Google Analytics data. We make additional API requests and merge them in case the results exceed the 10,000 limit.
def GAData(gaid, start, end, metrics, dimensions,
segment, token, max_results=10000):
“””Creates a generator that yields GA API data
in chunks of size `max_results`”””
#build uri w/ params
api_uri = “https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&”\
“start-date={start}&end-date={end}&metrics={metrics}&”\
“dimensions={dimensions}&segment={segment}&access_token={token}&”\
“max-results={max_results}”
# insert uri params
api_uri = api_uri.format(
gaid=gaid,
start=start,
end=end,
metrics=metrics,
dimensions=dimensions,
segment=segment,
token=token,
max_results=max_results
)
# Using yield to make a generator in an
# attempt to be memory efficient, since data is downloaded in chunks
r = requests.get(api_uri)
data = r.json()
yield data
if data.get(“nextLink”, None):
while data.get(“nextLink”):
new_uri = data.get(“nextLink”)
new_uri += “&access_token={token}”.format(token=token)
r = requests.get(new_uri)
data = r.json()
yield data
In the second function, we load the Google Analytics Query Explorer API response into a pandas DataFrame to simplify our analysis.
import pandas as pd
def to_df(gadata):
“””Takes in a generator from GAData()
creates a dataframe from the rows”””
df = None
for data in gadata:
if df is None:
df = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
else:
newdf = pd.DataFrame(
data[‘rows’],
columns=[x[‘name’] for x in data[‘columnHeaders’]]
)
df = df.append(newdf)
print(“Gathered {} rows”.format(len(df)))
return df
Now, we can call the functions to load the Google Analytics data.
data = GAData(gaid=gaid, metrics=metrics, start=start,
end=end, dimensions=dimensions, segment=segment,
token=token)
data = to_df(data)
Analyzing the data
Let’s start by just getting a look at the data. We’ll use the .head() method of DataFrames to take a look at the first few rows. Think of this as glancing at only the top few rows of an Excel spreadsheet.
data.head(5)
This displays the first five rows of the data frame.
Most of the data is not in the right format for proper analysis, so let’s perform some data transformations.
First, let’s convert the date to a datetime object and the metrics to numeric values.
data[‘ga:date’] = pd.to_datetime(data[‘ga:date’])
data[‘ga:users’] = pd.to_numeric(data[‘ga:users’])
data[‘ga:newUsers’] = pd.to_numeric(data[‘ga:newUsers’])
Next, we will need the landing page URL, which are relative and include URL parameters in two additional formats: 1) as absolute urls, and 2) as relative paths (without the URL parameters).
from urllib.parse import urlparse, urljoin
data[‘path’] = data[‘ga:landingPagePath’].apply(lambda x: urlparse(x).path)
data[‘url’] = urljoin(base_site_url, data[‘path’])
Now the fun part begins.
The goal of our analysis is to see which pages lost traffic after a particular date–compared to the period before that date–and which gained traffic after that date.
The example date chosen below corresponds to the exact midpoint of our start and end variables used above to gather the data, so that the data both before and after the date is similarly sized.
We begin the analysis by grouping each URL together by their path and adding up the newUsers for each URL. We do this with the built-in pandas method: .groupby(), which takes a column name as an input and groups together each unique value in that column.
The .sum() method then takes the sum of every other column in the data frame within each group.
For more information on these methods please see the Pandas documentation for groupby.
For those who might be familiar with SQL, this is analogous to a GROUP BY clause with a SUM in the select clause
# Change this depending on your needs
MIDPOINT_DATE = “2017-12-15”
before = data[data[‘ga:date’] < pd.to_datetime(MIDPOINT_DATE)]
after = data[data[‘ga:date’] >= pd.to_datetime(MIDPOINT_DATE)]
# Traffic totals before Shopify switch
totals_before = before[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_before = totals_before.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
# Traffic totals after Shopify switch
totals_after = after[[“ga:landingPagePath”, “ga:newUsers”]]\
.groupby(“ga:landingPagePath”).sum()
totals_after = totals_after.reset_index()\
.sort_values(“ga:newUsers”, ascending=False)
You can check the totals before and after with this code and double check with the Google Analytics numbers.
print(“Traffic Totals Before: “)
print(“Row count: “, len(totals_before))
print(“Traffic Totals After: “)
print(“Row count: “, len(totals_after))
Next up we merge the two data frames, so that we have a single column corresponding to the URL, and two columns corresponding to the totals before and after the date.
We have different options when merging as illustrated above. Here, we use an “outer” merge, because even if a URL didn’t show up in the “before” period, we still want it to be a part of this merged dataframe. We’ll fill in the blanks with zeros after the merge.
# Comparing pages from before and after the switch
change = totals_after.merge(totals_before,
left_on=”ga:landingPagePath”,
right_on=”ga:landingPagePath”,
suffixes=[“_after”, “_before”],
how=”outer”)
change.fillna(0, inplace=True)
Difference and percentage change
Pandas dataframes make simple calculations on whole columns easy. We can take the difference of two columns and divide two columns and it will perform that operation on every row for us. We will take the difference of the two totals columns, and divide by the “before” column to get the percent change before and after out midpoint date.
Using this percent_change column we can then filter our dataframe to get the winners, the losers and those URLs with no change.
change[‘difference’] = change[‘ga:newUsers_after’] – change[‘ga:newUsers_before’]
change[‘percent_change’] = change[‘difference’] / change[‘ga:newUsers_before’]
winners = change[change[‘percent_change’] > 0]
losers = change[change[‘percent_change’] < 0]
no_change = change[change[‘percent_change’] == 0]
Sanity check
Finally, we do a quick sanity check to make sure that all the traffic from the original data frame is still accounted for after all of our analysis. To do this, we simply take the sum of all traffic for both the original data frame and the two columns of our change dataframe.
# Checking that the total traffic adds up
data[‘ga:newUsers’].sum() == change[[‘ga:newUsers_after’, ‘ga:newUsers_before’]].sum().sum()
It should be True.
Results
Sorting by the difference in our losers data frame, and taking the .head(10), we can see the top 10 losers in our analysis. In other words, these pages lost the most total traffic between the two periods before and after the midpoint date.
losers.sort_values(“difference”).head(10)
You can do the same to review the winners and try to learn from them.
winners.sort_values(“difference”, ascending=False).head(10)
You can export the losing pages to a CSV or Excel using this.
losers.to_csv(“./losing-pages.csv”)
This seems like a lot of work to analyze just one site–and it is!
The magic happens when you reuse this code on new clients and simply need to replace the placeholder variables at the top of the script.
In part two, we will make the output more useful by grouping the losing (and winning) pages by their types to get the chart I included above.
The post Using Python to recover SEO site traffic (Part one) appeared first on Search Engine Watch.
from Search Engine Watch https://searchenginewatch.com/2019/02/06/using-python-to-recover-seo-site-traffic-part-one/
0 notes